
本文为《ASP.NET Core技术内幕与项目实战》的读书笔记,B站有配套视频,建议先阅读书籍。
第1章 .NET Core入门
.NET Core概述
.NET Core是微软推出的新一代跨平台开发技术,它吸收了.NET Framework的优点,又具有跨平台运行的特性。重要的是,.NET Core插上了云原生的翅膀,让开发人员可以开发能运行在容器环境中的微服务,以便于开发能应对高并发、高负载的系统。ASP.NET Core是在.NET Core平台下进行Web开发及后端接口开发的技术。
微软把.NET Core打造为可以在Windows、Linux、macOS等操作系统下开发和运行程序的框架;使用.NET Core开发的程序甚至可以运行在嵌入式设备上,这样.NET Core就成为物联网开发中的一个重要技术。
需要特别注意的是,.NET Core不是.NET Framework的升级版,而是一个从头开始开发的全新平台,因此在.NET Framework下开发的程序并不能直接在.NET Core下运行。
NET Core有如下优点。
(1).NET Core采用模块化开发。
(2).NET Core支持独立部署,也就是说,可以把.NET Core运行时环境和开发的程序打包到一起部署。这样就不需要在服务器上安装.NET Core运行环境,只要把程序复制到服务器上,程序就能运行,这对容器化、无服务器(Serverless)等非常友好。
(3)程序的运行效率更高。.NET Core的所有管道都是可以插拔的,我们可以决定程序需要哪些管道及它们的执行顺序,因此用.NET Core开发出来的程序运行效率更高。
(4)ASP.NET Core程序内置了简单且高效的Web服务器—Kestrel。
(5).NET Core更符合如今的软件设计思想。
.NET Standard是什么
.NET Standard规定了一系列需要被所有.NET Core、.NET Framework及Xamarin等共同实现的API,包括有哪些类、有哪些方法、参数和返回值是什么等。需要说明的是,.NET Standard只是一个规范,不是一个框架。不要以为.NET Standard是一个被.NET Framework、.NET Core、Xamarin等共用的基础库,.NET Standard只是规定了需要被实现的规范,但是不负责具体实现。
如果我们要编写一个给公众使用的类库,为了让.NET Core、.NET Framework、Xamarin等开发人员都能使用这个类库,这个类库就应该是.NET Standard类库,并且.NET Standard的版本应尽可能低一些,这样低版本的.NET Core、.NET Framework、Xamarin的项目也能使用这个类库。
如果发现开发时用到的类在这个.NET Standard版本中不存在,再逐步提升项目的.NET Standard版本。和其他类型的项目一样,.NET Standard类库的目标版本可以在项目属性的“目标框架”中选择
如果要开发项目内部使用的类库,并且这个类库只会被.NET Core项目引用
建议直接建立.NET Core类库项目,因为这样可以省去很多麻烦,而且可以使用.NET Core中一些特有的类和方法。
NET Standard是一个.NET平台下的规范,使得我们开发的类库可以被.NET Framework、.NET Core、Xamarin等使用,提高了代码的复用性。
从.NET 5开始,微软将不再更新.NET Standard,而是会把.NET 5、.NET 6等视为单一的代码库,并会通过编译期和运行时的检查来解决不同平台下它们所支持的功能具有差异这一问题。
.NET Core开发环境的搭建
在安装Visual Studio的时候,一定要勾选“ASP.NET和Web开发”这个模块。从Visual Studio 2022开始,微软开始淡化.NET Framework的概念,在项目向导中,只有使用带“.NET Framework”的项目模板创建的才是.NET Framework项目,使用其他模板创建的都是.NET Core项目。
在.NET Framework项目中,项目中所有的代码文件都要添加到.csproj文件中,如果一个C#文件放在项目文件夹下,但是没有被添加到.csproj文件中,那么这个文件是不会被编译的。但是.NET Core项目就不同了,.NET Core项目中的文件不用添加到*.csproj文件中,项目下所有的文件默认都被自动包含到项目中,除非被手动排除。.NET Framework和.NET Core项目还有一个不同之处就是.NET Core项目没有App.config或Web.config文件,因为.NET Core项目中的配置有不同的使用方式。
第2章 .NET Core重难点知识
C#的新语法
顶级语句
从C# 9.0开始,C#增加了“顶级语句”语法,它使得可以直接在C#文件中编写入口代码,不再需要声明类和方法。
由于顶级语句只是让编译器帮助开发人员简化工作,因此同一个项目中只能有一个文件具有顶级语句。顶级语句并不是用来替代原本的Main方法的,我们仍然可以用传统的Main方法编写入口代码。在顶级语句中,可以直接使用await语法调用异步方法,而且在顶级语句文件中也可以声明方法全局using指令
C# 10.0中增加了“全局using指令”语法,我们可以将global修饰符添加到任何using关键字前,这样通过using语句引入的命名空间就可以应用到这个项目的所有源代码中,因此同一个项目中的C#代码就不需要再去重复引入这个命名空间了。在实践中,通常创建一个专门用来编写全局using代码的C#文件,然后把所有在项目中经常用到的命名空间声明到这个C#文件中。
只要在*.csproj文件中加入了<ImplicitUsings>enable</ImplicitUsings>,编译器会根据项目类型自动为项目隐式地增加对System、System.Linq、Microsoft.AspNetCore.Http等常用命名空间的引入。using声明
C#中可以用using关键字来简化非托管资源的释放,当变量离开using作用的范围后,会自动调用对象的Dispose方法,从而完成非托管资源的释放。
在C# 8.0及之后的版本中,可以使用简化的“using声明”语法来避免代码的嵌套。
在声明变量的时候,如果类型实现了IDisposable或IAsyncDisposable接口,那么可以在变量声明前加上using关键字,这样当代码执行离开被using修饰的变量作用域的时候,变量指向的对象的Dispose方法就会被调用。
由于使用“using声明”语法声明的变量是在离开变量作用域的时候,比如方法执行结束时,才进行资源的回收,而不是像之前使用传统using语法那样可以由开发人员定义资源的回收时机,因此在使用它的时候要避免一些可能的陷阱。文件范围的命名空间声明
在之前版本的C#中,类型必须定义在命名空间中,而从C# 10.0开始,C#允许编写独立的namespace代码行声明命名空间,文件中所有的类型都是这个命名空间下的成员。这种语法能够减少C#源代码文件的嵌套层次可为空的引用类型
C# 8.0中提供了“可为空的引用类型”语法,可以在引用类型后添加“?”修饰符声明这个类型是可为空的。对于没有添加“?”修饰符的引用类型的变量,当编译器发现存在为这个变量赋值null的可能性的时候,编译器会给出警告信息。在Visual Studio 2022中,这个特性是默认启用的,可以通过删除项目*.csproj文件中的<Nullable>disable</Nullable>关闭这个特性。
当然,如果确认被访问的变量、成员不会出现为空的情况,也可以在访问可为空的变量、成员的时候加上!来抑制编译器的警告,当然,要尽量避免使用!抑制警告。记录类型
C#中的==运算符默认判断两个变量指向的是否是同一个对象。如果两个对象是同一种类型,并且所有属性完全相等,但是它们是两个不同的对象,导致==运算符的比较结果是false,则可以通过重写Equals方法、重写==运算符等来解决这个问题,不过这要求编写非常多的额外代码。在C# 9.0中增加了记录(record)类型的语法,编译器会自动生成Equals、GetHashcode等方法。
编译器同样会为record类型生成ToString方法和Equals方法等。
record类型编译后仍然只是一个普通的类,record是编译器提供的一个语法糖。
record类型提供了为所有属性赋值的构造方法,所有属性都是只读的,对象之间可以进行值的相等性比较,并且编译器为类型提供了可读性强的ToString方法。在需要编写不可变类并且需要进行对象值比较的时候,使用record可以把代码的编写难度大大降低。
在record类型中,也可以为类型提供多个构造方法,从而提供多种创造对象的途径。
record类型的对象的属性默认都是只读的,而且我们也推荐使用属性都为只读的类型。所有属性、成员变量都为只读的类型叫作“不可变类型”,不可变类型可以简化程序逻辑,并且可以减少并发访问、状态管理等麻烦。
异步编程
异步编程的优点就是可以提高服务器接待请求的数量,但不会使得单个请求的处理效率变高,甚至有可能略有降低。
用async关键字修饰方法后,这个方法就成了“异步方法”。异步方法有如下几点需要注意。
(1)异步方法的返回值一般是Task
(2)按照约定,异步方法的名字以Async结尾
(3)如果异步方法没有返回值,可以把返回值声明为void,这在语法上是成立的。但这样的代码在使用的时候有很多的问题,而且很多框架都要求异步方法的返回值不能为void,因此即使方法没有返回值,也最好把返回值声明为非泛型的Task类型。
(4)调用泛型方法的时候,一般在方法前加上await关键字,这样方法调用的返回值就是泛型指定的T类型的值。
(5)一个方法中如果有await调用,这个方法也必须修饰为async,因此可以说异步方法是有传染性的。
提醒:C# 9.0中新增的顶级语句允许直接在入口代码中使用await关键字,如果在不使用顶级语句的项目中,我们需要用async修饰Main方法,然后把方法的返回值修改为Task类型。
await关键字的意思是:调用异步方法,等异步方法执行结束后再继续向下执行。
总结:在调用异步方法的时候,一般都要加上await关键字。一个方法中如果有await关键字,则该方法也必须修饰为async。await关键字让我们可以用类似于同步的方式调用异步方法,从而简化异步编程。
async、await原理揭秘
async方法会被C#编译器编译成一个类,并根据await调用把方法切分为多个状态,对async方法的调用就会被拆分为若干次对MoveNext方法的调用。
async背后的线程切换
结论:在对异步方法进行await调用的等待期间,框架会把当前的线程返回给线程池,等异步方法调用执行完毕后,框架会从线程池再取出一个线程,以执行后续的代码。我们把这种由不同线程执行不同代码段的行为称作“线程切换”。
使用await、async进行异步调用的好处:当需要等待一个异步操作的时候,这个线程就会被放回线程池;当异步调用执行结束后,程序再从线程池取出一个线程来执行后续代码。因此服务器中的每个线程都不会空等某个操作,服务器处理并发请求的能力也就提升了。
总结:编译器把async拆分成多次方法调用,程序在运行的时候会通过从线程池中取出空闲线程执行不同MoveNext调用的方式来避免线程的“空等”,这样开发人员就可以像编写同步代码一样编写异步代码,从而提升系统的并发处理能力。
异步方法不等于多线程
异步方法的代码并不会自动在新线程中执行,除非把代码放到新线程中执行。把代码放到新线程中执行可以用Task.Run方法,也可以用Task.Factory.StartNew方法。
其实Task.Run就是对Task.Factory.StartNew方法的封装而已。
为什么有的异步方法没有async
对于async方法,编译器会把代码根据await调用分成若干片段,然后对不同片段采用状态机的方式切换执行。不过,这个语法糖有时候反而是一个负担,这时我们就可以编写不用async修饰的异步方法。
只要方法的返回值是Task类型,我们就可以用await关键字对其进行调用,而不用管被调用的方法是否用async修饰。
如果一个异步方法只是对别的异步方法进行简单的调用,并没有太多复杂的逻辑,比如获取异步方法的返回值后再做进一步的处理,就可以去掉async、await关键字。
对于使用async的异步方法,如果返回值是Task类型,我们可以直接用return结束方法的执行。
但是在编写不用async修饰的异步方法时,则需要开发人员手动创建Task对象。
异步编程的几个重要问题
(1).NET Core的类库已经全面拥抱异步了,
建议开发人员只使用异步方法,因为这样能提升系统的并发处理能力。
(2)在.NET Framework时代,由于历史遗留问题,还是有一些地方不能使用async,但是在.NET Core时代,我们很少会遇到这种情况,因此请读者统一用await调用异步方法。
(3)异步暂停的方法。如果想在异步方法中暂停一段时间再继续执行,那么不要用Thread.Sleep,因为它会阻塞调用线程,要使用await Task.Delay。
(4).NET Core的很多异步方法中都有一个CancellationToken类型的参数,我们可以通过CancellationToken类型的对象让异步方法提前终止。
(5)可以使用Task.WhenAll同时等待多个Task的执行结束。
.NET中还提供了一个Task.WhenAny方法用于等待多个任务,只要其中任何一个任务执行完成,代码就会继续向下执行。
(6)由于async用于提示编译器为异步方法中的await代码进行分段处理,而且一个异步方法是否用async修饰对于方法的调用者来说是没有区别的,因此对于接口中的方法或者抽象方法是不能修饰为async的,但是这些方法仍然可以把返回值设置为Task类型,在实现类中再根据需要为实现方法添加async关键字的修饰。
LINQ
LINQ是.NET Core中提供的简化数据查询的技术。使用LINQ技术,可以用几行代码就实现复杂的数据查询。
Lambda表达式
Lambda表达式是C#中的语法,它可以让我们进行函数式编程,可大大减少代码量。
委托是一种可以指向方法的类型,委托类型规定了方法的返回值和参数的类型。
在.NET中定义了最多可达16个参数的泛型委托Action(无返回值)和Func(有返回值),因此一般我们不需要自定义委托类型,可以直接使用Action或者Func这两个委托类型。委托变量不仅可以指向普通方法,也可以指向匿名方法。
常用集合类的扩展方法
LINQ关键的功能是提供了集合类的扩展方法,所有实现了
IEnumerable<T>接口的类都可以使用这些方法。这些方法不是IEnumerable<T>中的方法,而是以扩展方法的形式存在于System.Linq命名空间的静态类中。LINQ中常用的集合类的扩展方法
(1)数据过滤。Where方法是用于根据条件对数据进行过滤的。
Where方法是一个Lambda表达式格式的匿名方法,方法的参数e表示当前待判断的元素值。参数的名字不一定非要是e,只要不违反变量的命名规则并且不和作用域内的其他变量名冲突即可,不过一般Lambda表达式中的变量名长度都不长,一般都是一个字符,这样可以避免Lambda表达式的代码太长。
(2)获取数据条数。Count方法用于获取数据条数,它有两个重载方法,一个没有参数,另一个有
Func<TSource,bool>predicate类型参数。没有参数的重载方法用于获取集合的数据条数,而有predicate参数的则可以获取集合中符合predicate条件的数据条数。(3)判断是否至少有一条满足条件的数据。Any方法用于判断集合中是否至少有一条满足条件的数据,返回值为bool类型。Any方法同样有两个重载方法,一个是没有参数的,另一个是有
Func<TSource,bool>predicate类型参数的。在执行的时候,Any只要遇到一个满足条件的数据就停止继续向后检查数据,但是Count则要一直计算到最后一条才能知道满足条件的数据条数,因此通常用Any实现的效率比用Count实现的更高。如果只是想判断数据是否存在,请使用Any方法。
(4)获取一条数据。LINQ中有4组获取一条数据的方法,分别是
Single、SingleOrDefault、First和FirstOrDefault。这4组方法的返回值都是符合条件的一条数据,每组方法也同样有两个重载方法,一个没有参数,另一个有一个Func<TSource,bool>predicate参数。这4组方法的区别:
Single:如果确认有且只有一条满足要求的数据,那么就用Single方法。如果没有满足条件的数据,或者满足条件的数据多于一条,Single方法就会抛出异常。SingleOrDefault:如果确认最多只有一条满足要求的数据,那么就用SingleOrDefault方法。如果没有满足条件的数据,SingleOrDefault方法就会返回类型的默认值。如果满足条件的数据多于一条,SingleOrDefault方法就会抛出异常。First:如果满足条件的数据有一条或者多条,First方法就会返回第一条数据;如果没有满足条件的数据,First方法就会抛出异常。FirstOrDefault:如果满足条件的数据有一条或者多条,FirstOrDefault方法就会返回第一条数据;如果没有满足条件的数据,FirstOrDefault方法就会返回类型的默认值。如果确认能且只能查出来一条满足条件的数据,那么就可以用Single方法。这样,如果程序数据有问题,导致有不止一条满足条件的数据,程序就能及时报错,帮助我们及早发现程序逻辑上的错误。一个健壮的程序,不应该隐藏异常,而是有了异常要及早暴露出来,以避免引起更大的问题。
(5)排序。OrderBy方法可以对数据进行正向排序,而OrderByDescending方法则可以对数据进行逆向排序
(6)限制结果集。限制结果集用来从集合中获取部分数据,其主要应用场景是分页查询。Skip(n)方法用于跳过n条数据,Take(n)方法用于获取n条数据。
(7)聚合函数。Max、Min、Average、Sum和Count,如果集合是int等值类型的集合,我们也可以使用没有参数的聚合函数。
(8)分组。LINQ中支持类似于SQL中的group by实现的分组操作。GroupBy方法用来进行分组
C#中的var是一个能让编译器根据变量上下文环境推测变量类型的语法,它可以帮开发人员避免编写
IEnumerable<IGrouping<int,Employee>>等过于复杂的变量类型,特别是与匿名类型结合起来使用非常方便,因此var在编写LINQ相关代码的时候用得非常多。(9)投影。可以对集合使用Select方法进行投影操作,通俗来说就是把集合中的每一项逐项转换为另外一种类型,Select方法的参数是转换的表达式
(10)集合转换。集合操作的扩展方法的返回值大部分都是IEnumerable
类型,但是有一些地方需要数组类型或者List 类型的变量,我们可以用ToArray和ToList方法分别把IEnumerable 转换为数组类型和List 类型 上面讲的这些方法中,Where、Select、OrderBy、GroupBy、Take、Skip等方法的返回值都是IEnumerable
类型,因此它们是可以被链式调用的。 LINQ的另一种写法
使用Where、OrderBy、Select等扩展方法进行数据查询的写法叫作“方法语法”。除此之外,LINQ还有另外一种叫作“查询语法”的写法。
查询语法”则是新的C#语法。C#编译器会把“查询语法”编译成“方法语法”形式,也就是在运行时它们没有区别。
“查询语法”看起来更新颖,而且比“方法语法”需要写的代码会少一些,但是在编写复杂的查询条件的时候,用“方法语法”编写的代码会更清晰。
第3章 .NET Core核心基础组件
依赖注入
控制反转(inversion of control,IoC)是设计模式中非常重要的思想,而依赖注入(dependency injection,DI)是控制反转思想的一种重要的实现方式。依赖注入简化了模块的组装过程,减小了模块之间的耦合度,因此.NET Core中大量应用了依赖注入的开发模式。
控制反转的目的就是把“创建和组装对象”操作的控制权从业务逻辑的代码中转移到框架中,这样业务代码中只要说明“我需要某个类型的对象”,框架就会帮助我们创建这个对象。框架甚至可以用装饰者模式把原始的对象包装起来,透明地提供权限控制、缓存、日志等功能,从而实现面向切面编程。
我们把负责提供对象的注册和获取功能的框架叫作“容器”,注册到容器中的对象叫作“服务”(service)。
控制反转就是把“我创建对象”,变成“我要对象”。实现控制反转的时候,我们可以采用依赖注入或者服务定位器两种方式。程序启动的时候,需要把服务注册到容器中,由容器负责服务的管理。
.NET Core依赖注入的基本使用:
依赖注入框架中注册的服务有一个重要的概念叫作“生命周期”,通俗地说就是“获取服务的时候是创建一个新对象还是用之前的对象”。
依赖注入框架中服务的生命周期有3种:
(1)瞬态(transient):每次被请求的时候都会创建一个新对象。适合有状态的对象,可以避免多段代码用于同一个对象而造成状态混乱,其缺点是生成的对象比较多,会浪费内存。
(2)范围(scoped):在给定的范围内,多次请求共享同一个服务对象,服务每次被请求的时候都会返回同一个对象;在不同的范围内,服务每次被请求的时候会返回不同的对象。这种方式适用于在同一个范围内共享同一个对象的情况。
(3)单例(singleton):全局共享同一个服务对象。可以节省创建新对象的资源。为了避免并发修改等问题,单例的服务对象最好是无状态对象。
依赖注入框架是根据服务的类型来获取服务的,依赖注入框架中注册服务的时候可以分别指定服务类型和实现类型,这两者可能相同,也可能不同。
在面向对象编程中,推荐使用面向接口编程,这样我们的代码就依赖于服务接口,而不是依赖于实现类,可以实现代码解耦。因此在使用依赖注入的时候,推荐服务类型用接口类型。
再次强调,不要在长生命周期的对象中引用比它短的生命周期的对象。比如不能在单例服务中引用范围服务,否则可能会导致被引用的对象已经释放或者导致内存泄漏。在ASP.NET Core的默认依赖注入容器中,这种“在长生命周期的对象中引用短生命周期的对象”的代码会引发异常。
依赖注入的魅力所在:
.NET Core的DependencyInjection框架的亮点是依赖注入,也就是由框架帮我们进行服务的获取。依赖注入是有“传染性”的,如果一个类的对象是通过依赖注入创建的,那么这个类的构造方法中声明的所有服务类型的参数都会被依赖注入赋值;但是如果一个对象是由开发人员手动创建的,这个对象就和依赖注入没有关系,它的构造方法中声明的服务类型参数不会被自动赋值。因此,一旦使用依赖注入,就要尽量避免直接通过new关键字来创建对象。还可以通过在构造方法中声明多个服务类型来注入多个服务;如果有一个服务有多个实现对象,可以把参数声明为IEnumerable
配置系统
配置系统的基本使用
.NET Core中的配置系统支持非常丰富的配置源,包括文件(JSON、XML、INI等)、注册表、环境变量、命令行、Azure Key Vault等,配置系统还支持自定义配置源。.NET Core中读取配置有很多种方式,既可以通过IConfigurationRoot读取配置,也可以使用绑定的方式把配置读取为一个C#对象。.NET Core中配置系统的基础开发包是Microsoft.Extensions.Configuration。
使用选项方式读取配置
使用选项方式读取配置是.NET Core中推荐的方式,因为它不仅和依赖注入机制结合得更好,而且它可以实现配置修改后自动刷新,所以使用起来更方便。使用选项方式读取配置需要通过NuGet为项目安装Microsoft.Extensions.Options。由于这种方式是对绑定方式的封装,因此我们仍然需要同时安装包Microsoft.Extensions.Configuration.Binder。
由于使用选项方式读取配置的时候,需要和依赖注入一起使用,因此我们需要创建一个类用于获取注入的选项值。声明接收选项注入的对象的类型。要使用IOptions<T>、IOptionsMonitor<T>、IOptionsSnapshot<T>等泛型接口类型,因为它们可以帮我们处理容器生命周期、配置刷新等。
通俗地说,在一个范围内,如果有A、B两处代码都读取了某个配置项,在运行A之后且在运行B之前,这个配置项改变了,那么如果我们用IOptionsMonitor
由于IOptions
IOptions 是单例,因此一旦生成了,除非通过代码的方式更改,它的值是不会更新的。
IOptionsMonitor 也是单例,但是它通过IOptionsChangeTokenSource 能够和配置文件一起更新,也能通过代码的方式更改值。
IOptionsSnapshot 是范围,所以在配置文件更新的下一次访问,它的值会更新,但是它不能跨范围通过代码的方式更改值,只能在当前范围(请求)内有效。
一般来说,如果你依赖配置文件,那么首先考虑IOptionsMonitor ,如果不合适接着考虑IOptionsSnapshot ,最后考虑IOptions 。
有一点需要注意,在ASP.NET Core应用中IOptionsMonitor可能会导致同一个请求中选项的值不一致——当你正在修改配置文件的时候——这可能会引发一些奇怪的bug。
如果这个对你很重要,请使用IOptionsSnapshot,它可以保证同一个请求中的一致性,但是它可能会带来轻微的性能上的损失。
参考:https://www.cnblogs.com/wenhx/p/ioptions-ioptionsmonitor-and-ioptionssnapshot.html
从命令行读取配置
通过命令行读取配置特别适合容器化的运行环境,因为容器中给应用程序传递配置最方便的方式之一就是通过命令行。
要从命令行读取配置,除了要通过NuGet安装Microsoft.Extensions.Configuration之外,还要安装Microsoft.Extensions.Configuration.CommandLine包,然后在ConfigurationBuilder对象上调用AddCommandLine方法即可
如果每次我们都要到命令行窗口下为程序传递参数的话,开发的时候会很麻烦。Visual Studio中提供了一个可以设置命令行参数的选项。在项目的属性的【调试】选项卡中,可以在【从命令行读取配置】中设置命令行参数,这样在Visual Studio中调试、运行程序的时候,Visual Studio会自动把这里设定的参数以命令行参数的形式传递给程序
从环境变量读取配置
.NET Core中从环境变量读取配置需要安装Microsoft.Extensions.Configuration.EnvironmentVariables包,然后调用AddEnvironmentVariables方法进行注册即可。AddEnvironmentVariables方法存在无参数和有prefix参数两个重载版本,无参数版本会将所有环境变量都加载进来,但是由于系统中的环境变量非常多,这样容易和其他程序的环境变量产生冲突,因此建议读者使用有prefix参数的AddEnvironmentVariables重载方法进行注册。prefix指的是环境变量名字的前缀,程序会加载所有名字中包含该前缀的环境变量,这样就把其他无关的环境变量排除了。在代码中读取环境变量的时候忽略这个前缀即可。
其他配置提供程序
.NET Core的配置系统是开放的,允许我们开发第三方的配置提供程序。比如Apollo是携程网开源的一个配置管理平台,提供了灰度发布、权限控制、审核等复杂的配置管理功能,已经在携程网之外的很多互联网公司落地,是目前国内应用非常广泛的一个配置管理平台。
多配置源问题
.NET Core中的配置系统支持“可覆盖的配置”,也就是我们可以向ConfigurationBuilder中注册多个配置提供程序,后添加的配置提供程序可以覆盖先添加的配置提供程序。
当配置提供程序和配置项比较多的时候,我们可能需要查看一下最终读到的配置项的值来自哪个配置提供程序。可以调用IConfigurationRoot的扩展方法GetDebugView,它会返回一个包含配置项来源,即配置提供程序信息的字符串。
日志
.NET Core日志基本使用
.NET Core中的日志系统可以把日志记录到控制台、事件日志、调试窗口等地方,还可以使用第三方日志提供程序把日志记录到文件、日志服务器等地方。和配置系统一样,.NET Core中的日志提供了标准接口及官方的一些实现,同时允许开发人员编写第三方实现。
日志系统核心的开发包是Microsoft.Extensions.Logging,
如果使用控制台输出日志的方式,还要为程序安装Microsoft.Extensions.Logging.Console包。
ILogger中有LogTrace、LogDebug、LogInformation、LogWarning、LogError、LogCritical这6组方法用于输出不同严重性级别的消息(严重性级别依次提高)。
文件日志提供程序NLog
.NET Core并没有内置的文本文件日志提供程序,我们需要使用第三方的日志提供程序。常用的第三方日志提供程序有Log4Net、NLog、Serilog。这里推荐使用NLog或者Serilog,因为它们不仅使用简单,而且功能强大。
集中式日志
在分布式环境下,我们最好采用集中式的日志服务器,各台服务器都把产生的日志写入日志服务器。
如果系统运行在自己的数据中心,或者我们不想使用云服务提供的集中式日志系统,那么也可以使用自行托管的集中式日志系统。
推荐两个开源项目—Exceptionless和ELK。
第4章 Entity Framework Core基础
Entity Framework Core(简称EF Core)是.NET Core中的ORM(object relational mapping,对象关系映射)框架,它可以让开发人员以面向对象的方式进行数据库操作,从而大大提高开发效率。
EF Core概述
ORM(object relational mapping,对象关系映射)中的“对象”指的就是C#中的对象,而“关系”指的是关系数据库,“映射”指的是在关系数据库和C#对象之间搭建一座“桥梁”。
在.NET中可以通过ADO.NET连接数据库然后执行SQL语句来操作数据库中的数据。而ORM可以让我们通过操作C#对象的方式操作数据库
提醒:ORM只是对ADO.NET的封装,ORM底层仍然是通过ADO.NET访问数据库的。
使用EF Core可以帮助开发人员更快地完成项目,这就是非常大的优势;对于性能瓶颈环节,开发人员可以再使用EF Core进行优化;对于使用EF Core优化后性能还较差的环节,开发人员还可以把EF Core代码改为直接执行SQL语句。
EF Core入门
EF Core支持所有主流的数据库,包括Microsoft SQL Server、Oracle、MySQL、PostgreSQL、SQLite等数据库,而且EF Core的接口标准是开放的,只要按照标准去实现EF Core Database Provider(数据库提供程序),就可以对其他数据库添加EF Core的支持。
在经典的EF Core使用场景下,由开发人员编写实体类,然后EF Core可以根据实体类生成数据库表
这种先创建实体类再生成数据库表的开发模式叫作“模型驱动开发”,区别于先创建数据库表后创建实体类的“数据驱动开发”。EF Core这种根据实体类生成数据库表的操作也被叫作“迁移”(migration)。
为了使用EF Core生成数据库的工具,我们需要通过NuGet为项目安装Microsoft.EntityFrameworkCore.Tools包
Add-Migration InitialCreate就是一个数据库迁移命令,它的作用是根据实体类及配置生成操作数据库的迁移代码,其中的InitialCreate是开发人员给这次迁移取的名字,只要符合C#标识符命名规则,这个名字可以随意取,但是建议取一个能反映这次变化的、有意义的名字。Migrations文件夹下C#代码的文件的名字就是由“Id+迁移名字”组成的。Update-database命令用于对当前连接的数据库执行所有未应用的数据库迁移代码,命令执行成功后,数据库中的表结构等就和项目中实体类的配置保持一致了。
使用EF Core,还可以对已有的数据进行修改、删除操作。常规来讲,如果要对数据进行修改,我们首先需要把要修改的数据查询出来,然后对查询出来的数据进行修改,再执行SaveChangesAsync保存修改即可。
同样,要对数据进行删除,我们要先把待删除的数据查询出来,然后调用DbSet或者DbContext的Remove方法把数据删除,再执行SaveChangesAsync方法保存结果到数据库。
EF Core的实体类配置
约定大于配置
为了减少配置工作量,EF Core采用了“约定大于配置”的设计原则,也就是说EF Core会默认按照约定根据实体类以及DbContext的定义来实现和数据库表的映射配置,除非用户显式地指定了配置规则。
几个主要的约定规则:
规则1:数据库表名采用上下文类中对应的DbSet的属性名。
规则2:数据库表列的名字采用实体类属性的名字,列的数据类型采用和实体类属性类型兼容的类型
规则3:数据库表列的可空性取决于对应实体类属性的可空性。EF Core 6中支持C#中的可空引用类型。规则4:名字为Id的属性为主键,如果主键为short、int或者long类型,则主键默认采用自动增长类型的列。
Data Annotation
Data Annotation(数据注释)指的是可以使用.NET提供的Attribute[1]对实体类、属性等进行标注的方式来实现实体类配置。
Fluent API
Fluent API属于官方的推荐用法,主要有以下两点原因。
(1)Fluent API能够更好地进行职责分离。
(2)Fluent API的功能更强大。
Data Annotation和Fluent API是可以一起使用的。如果同样的内容用这两种方式都配置了,那么Fluent API的优先级高于Data Annotation的优先级。
默认情况下,一个实体类的所有属性都会映射到数据库表中,如果想让EF Core忽略一个属性,就可以用Ignore配置。数据库表中的列名默认和属性名一样,我们可以使用HasColumnName方法配置一个不同的列名。使用HasColumnType为列指定数据类型。
EF Core默认把名字为Id或者“实体类型+Id”的属性作为主键,我们可以用HasKey配置其他属性作为主键。
EF Core中可以用HasIndex方法配置索引。
EF Core也支持多个属性组成的复合索引,只要给HasIndex方法传递由一个或多个属性的名字组成的匿名类对象即可。
默认情况下,EF Core中定义的索引不是唯一索引,我们可以用IsUnique方法把索引配置为唯一索引。我们还可以用IsClustered方法把索引设置为聚集索引。
在数据库设计中,对于主键类型来讲,有自动增长(简称自增)的long类型和Guid类型两种常用的方案。
自增long类型占用磁盘空间小,可读性强,但是自增long类型的主键在数据库迁移以及分布式系统(如分库分表、数据库集群)中使用起来比较麻烦,而且在高并发插入的时候性能比较差。由于自增列的值一般都是由数据库生成的,因此无法提前获得新增数据行的主键值,我们需要把数据保存到数据库之后才能获得主键的值。
Guid算法使用网卡的MAC(medium access control,介质访问控制)地址、时间戳等信息生成一个全球唯一的ID。它适用于分布式系统,在进行多数据库数据合并的时候很方便,值得注意的是,由于Guid算法生成的值是不连续的(即使是SQL Server中NewSequentialId函数生成的Guid也不能根本解决这个问题),因此我们在使用Guid类型作为主键的时候,不能把主键设置为聚集索引。
在SQL Server中,可以设置主键为非聚集索引,但是使用其他数据库管理系统的时候,也请先查阅在对应的数据库管理系统中,是否可以把主键设置为非聚集索引。
使用Guid类型主键,我们不需要将数据插入数据库就能提前知道主键的值,这样在开发一些需要用到新增数据主键值的场景下更加方便。
自增+Guid算法:就是表有两个主键(注意不是复合主键),用自增列作为物理主键,而用Guid列作为逻辑主键。物理主键是在进行表结构设计的时候把自增列设置为主键,而从表结构上我们是看不出来Guid列是主键的,但是在和其他表关联及和外部系统通信的时候(比如前端显示数据的标识的时候),我们都使用Guid列。这样不仅保证了性能,利用了Guid的优点,而且减少了主键自增导致主键值可被预测带来的安全性问题。
Hi/Lo算法:
EF Core支持使用Hi/Lo算法来优化自增列的性能。Hi/Lo算法的高位由服务器生成,因此保证了不同进程或者集群中不同服务器获取的高位值不会重复,而本地进程计算的低位则可以保证在本地高效率地生成主键值。
Hi/Lo算法不是EF Core的标准,如果使用的不是SQL Server数据库,则需要检查对应数据库的EF Core数据库提供程序是否提供了对Hi/Lo算法的支持。
数据库迁移
每次执行Add-Migration之后,Migrations文件夹下都会生成两个文件,一个文件的名字为“数字迁移名字.cs”,另一个文件的名字为“数字迁移名字.Designer.cs”,我们把每一次执行Add-Migration称作一次“迁移”。这些以数字开头的一组文件就对应了一次迁移,这些迁移开头的数字就是迁移的版本号,这些版本号是递增的,因此我们根据版本号对其进行排序就能得知数据库迁移的历史。
对当前连接的数据库执行版本号更高的迁移叫作“向上迁移”,执行把数据库回退到旧版本的迁移叫“向下迁移”。
由于数据库迁移工具需要调用代码编译后的DLL文件去执行数据库迁移逻辑,因此在运行数据库迁移命令的时候,迁移工具会先尝试构建项目,如果项目构建失败,则迁移工作不能继续执行。
如果解决方案中有多个项目,在执行Add-Migration等命令的时候,一定要确认在【程序包管理器控制台】中选中的是要迁移的项目。
可以用Remove-migration命令删除最后一次的迁移脚本。
我们可以用Update-database命令执行迁移脚本来自动修改数据库,但是这种方式只适合在开发环境下使用,而不能用于生产环境。
EF Core中提供了Script-Migration命令来根据迁移代码生成SQL脚本,
这个脚本可以被提交给相关人员审计,然后在生产数据库中执行。
如果生产数据库已经处于某个迁移版本的状态了,那么我们可以生成这个版本到某个新版本的SQL脚本。比如当前数据库的前一版本是D,通过如下命令可以生成版本D到版本F的SQL脚本:Script-Migration D F。
查看EF Core生成的SQL语句
在EF Core 5.0之前,我们需要使用标准的日志框架输出EF Core背后执行的SQL语句。而从EF Core 5.0开始,EF Core增加了一种“简单日志”,
我们只要在上下文的OnConfiguring方法中调用optionsBuilder类的LogTo方法,传递一个参数为String的委托即可。当相关日志输出的时候,对应的委托就会被执行,这样我们就可以把包含底层执行的SQL语句在内的EF Core的日志输出到控制台。
如果一个项目需要同时面向多种类型的数据库进行开发,我们可以通过给Add-Migration命令添加“-OutputDir”参数的形式来在同一个项目中为不同的数据库生成不同的迁移脚本,并且把迁移脚本保存到不同的文件夹下,具体用法可以参考微软官方文档的“使用多个提供程序进行迁移”这一节。
MySQL的EF Core数据库提供程序有MySql.EntityFrameworkCore(以下简称“官方库”)、Pomelo.EntityFrameworkCore.MySql(以下简称“Pomelo”)这两个NuGet包。第一个是由MySQL官方开发和维护的,不是开源的;第二个是由Pomelo Foundation开源团队开发的,是开源的。
Npgsql.EntityFrameworkCore.PostgreSQL是PostgreSQL的EF Core提供程序,这个开源项目的主要贡献者也是微软EF Core团队的主力开发人员,因此这个项目的可靠性还是比较高的。
尽管EF Core帮开发人员完成了C#代码到SQL语句的翻译,在程序遇到bug或者性能瓶颈的时候,开发人员仍然需要关注EF Core生成的SQL语句,并且进行相应的优化。
关系配置
作为一个ORM框架,EF Core不仅能帮助开发人员简化单张表的处理,在处理表之间的关系上也非常强大。EF Core支持一对多、多对多、一对一等关系。
EF Core中实体类之间关系的配置采用如下的模式:HasXXX(…).WithYYY(…);。
其中HasXXX(…)用来设置当前这个实体类和关联的另一个实体类的关系,WithYYY(…)用来反向配置实体类的关系。XXX、YYY有One和Many这两个可选值。
EF Core的关系配置不仅能帮我们简化数据的插入,也可以简化关联数据的获取。
注意,Include方法是定义在Microsoft.EntityFrameworkCore命名空间中的扩展方法。
起到关联查询作用的就是Include方法,它用来生成对其他关联实体类的查询操作。
EF Core默认使用Join操作进行关联对象数据的加载,在有的情况下Join的性能会比较低。从EF Core 5.0开始,我们可以通过“拆分查询”实现在单独的查询中加载关联对象的数据,可以查看EF Core文档中AsSplitQuery部分的内容了解其用法。
EF Core会根据命名规则为“一对多”的“多”端的实体类创建一个外键列。
双向导航让我们可以通过任何一方的对象获取对方的信息,但是有时候我们不方便声明双向导航。
需要一种只在“多端”声明导航属性,而不需要在“一端”声明导航属性的单向导航机制。这种单向导航属性的配置其实很简单,只要在WithMany方法中不指定属性即可。
对于一对一关系,由于双方是“平等”的关系,外键列可以建在任意一方,因此我们必须显式地在其中一个实体类中声明一个外键属性。
由于双方都是一端,因此使用HasOne(…).WithOne(…)进行配置。
通过HasForeignKey方法声明外键对应的属性。
在EF Core的旧版本中,我们只能通过两个一对多关系模拟实现多对多关系。从EF Core 5.0开始,EF Core提供了对多对多关系的支持。
多对多指的是A实体类的一个对象可以被多个B实体类的对象引用,B实体类的一个对象也可以被多个A实体类的对象引用。
一对多和一对一都只要在表中增加外键列即可,但是在多对多关系中,我们必须引入一张额外的数据库表保存两张表之间的对应关系。
通过AddRange方法把多个对象批量加入上下文中。需要注意的是,AddRange只是循环调用Add把多个实体类加入上下文,是对Add方法的简化调用,在使用SaveChangesAsync的时候,这些实体类仍然是被逐条地插入数据库中的。
第5章 EF Core高级技术
5.1 EF Core原理揭秘
在使用EF Core的时候,一旦遇到EF Core无法支持的C#语法,可以尝试变换不同的写法直到能够被其支持为止。如果一条C#语句无论怎么写都不被EF Core支持,EF Core中也是可以直接编写原生SQL语句的
既生IEnumerable,何生IQueryable
使用SQL语句在数据库服务器上完成数据筛选的过程叫作“服务器端评估”;把数据首先加载到应用程序的内存中,然后在内存中进行数据筛选的过程叫作“客户端评估”。很显然,对于大部分情况来讲,“客户端评估”性能比较低,我们要尽量避免“客户端评估”。
Enumerable类中定义的供普通集合用的Where等方法都是“客户端评估”
Queryable中定义的Where方法则支持把LINQ查询转换为SQL语句。因此,在使用EF Core的时候,为了避免“客户端评估”,我们要尽量调用IQueryable版本的方法,而不是直接调用IEnumerable版本的方法。
IQueryable不仅可以带来“服务器端评估”这个功能,而且提供了延迟执行的能力。
其实,IQueryable只是代表“可以放到数据库服务器中执行的查询”,它没有立即执行,只是“可以被执行”而已。这一点其实可以从IQueryable类型名的英文含义看出来,“IQueryable”的意思是“可查询的”,可以查询,但是没有执行查询,查询的执行被延迟了。
除了遍历IQueryable操作之外,还有ToArray、ToList、Min、Max、Count等立即执行方法;GroupBy、OrderBy、Include、Skip、Take等方法是非立即执行方法。判断一个方法是否是立即执行方法的简单方式是:一个方法的返回值类型如果是IQueryable类型,这个方法一般就是非立即执行方法,否则这个方法就是立即执行方法。
我们可以调用非立即执行方法向IQueryable中添加查询逻辑,当执行立即执行方法的时候才真正生成SQL语句执行查询。
IQueryable是一个待查询的逻辑,因此它是可以被重复使用的。
ADO.NET中有DataReader和DataTable两种读取数据库查询结果的方式。如果查询结果有很多条数据,DataTable会把所有数据一次性地从数据库服务器加载到客户端内存中,而DataReader则会分批从数据库服务器读取数据。DataReader的优点是客户端内存占用小,缺点是如果遍历读取数据并进行处理的过程缓慢的话,会导致程序占用数据库连接的时间较长,从而降低数据库服务器的并发连接能力;DataTable的优点是数据被快速地加载到了客户端内存中,因此不会较长时间地占用数据库连接,缺点是如果数据量大的话,客户端的内存占用会比较大。
其实IQueryable内部的遍历就是在调用DataReader进行数据读取。因此,在遍历IQueryable的过程中,它需要占用一个数据库连接。
如果需要一次性把所有数据都读取到客户端内存中,可以用IQueryable的ToArray、ToArrayAsync、ToList、ToListAsync等方法。
在进行日常开发的时候,我们直接遍历IQueryable即可。但是如果方法需要返回查询结果或者需要多个查询嵌套执行,就要考虑把数据一次性加载到内存的方式,当然一次性查询的数据不能太多,以免造成过高的内存消耗。
如何执行原生SQL语句
1.执行SQL非查询语句
通过dbCtx.Database.ExecuteSqlInterpolated或者异步的dbCtx.Database.ExecuteSqlInterpolatedAsync方法执行原生的SQL非查询语句
2.执行实体类SQL查询语句
如果我们要执行的SQL语句是一个查询语句,并且查询的结果也能对应一个实体类,就可以调用对应实体类的DbSet的FromSqlInterpolated方法执行一个SQL查询语句,方法的参数是FormattableString类型,因此同样可以使用字符串内插传递参数。
由于IQueryable这种强大的“查询再加工”能力,我们可以把只能用原生SQL语句写的逻辑用FromSqlInterpolated执行,然后把分页、分组、二次过滤、排序、Include等其他逻辑仍然使用EF Core的标准操作实现。
FromSqlInterpolated的使用有如下局限性:
- SQL查询必须返回实体类型对应数据库表的所有列。
- 查询结果集中的列名必须与属性映射到的列名匹配。
- SQL语句只能进行单表查询,不能使用Join语句进行关联查询,但是可以在查询后面使用Include方法进行关联数据的获取。
3.执行任意SQL查询语句
我们可以通过dbCxt.Database.GetDbConnection获得一个数据库连接,然后就可以直接调用ADO.NET的相关方法执行任意的SQL语句了。由于ADO.NET是比较底层的API,使用起来非常麻烦,可以使用Dapper等轻量级的ORM工具简化对ADO.NET的调用
怎么知道实体类变化了
EF Core默认采用“快照更改跟踪”实现实体类改变的检测。
实体类有如下5种可能的状态:
已添加(Added)
未改变(Unchanged)
已修改(Modified)
已删除(Deleted)
分离(Detached)
我们可以使用上下文的Entry方法获得一个实体类在EF Core中的跟踪信息对象EntityEntry。EntityEntry类的State属性代表实体类的状态,而通过DebugView.LongView属性我们可以看到实体类的状态变化信息
EF Core的性能优化利器
EF Core优化之AsNoTracking
上下文不仅会跟踪对象的状态改变,还会通过快照的方式记录实体类的原始值,这是比较消耗资源的。因此,如果开发人员能够确认通过上下文查询出来的对象只是用来展示,不会发生状态改变,那么可以使用AsNoTracking方法告诉IQueryable在查询的时候“禁用跟踪”。
Find和FindAsync方法
Find或者FindAsync方法(以下简称为Find)会先在上下文查找这个对象是否已经被跟踪,如果对象已经被跟踪,就直接返回被跟踪的对象,只有在本地没有找到这个对象时,EF Core才去数据库查询,而Single方法则一直都是执行一次数据库查询。因此用Find方法有可能减少一次数据库查询,性能更好。但是如果在对象被跟踪之后,数据库中对应的数据已经被其他程序修改了,则Find方法可能会返回旧数据。
EF Core中高效地删除、更新数据
ExecuteUpdate 和 ExecuteDelete 是一种将数据保存到数据库的方法,无需使用 EF 的传统更改跟踪和 SaveChanges() 方法。(EF Core 7.0 中已引入此功能。)
全局查询筛选器
EF Core会自动将全局查询筛选器应用于涉及这个实体类型的所有LINQ查询。这个功能常见的应用场景有“软删除”和“多租户”。
实体类增加一个bool类型的属性IsDeleted,如果对应的数据被标记为已删除,那么IsDeleted的值就是true,否则就是false。
实体类的Fluent API配置中增加下面一句代码:builder.HasQueryFilter(b=>b.IsDeleted==false)。
如果在一些特殊查询中,需要查询被软删除的数据,可以在查询中使用IgnoreQueryFilters临时忽略全局查询筛选器。
如果启用了软删除,查询操作可能会导致全表扫描,从而影响查询性能,而如果为软删除列创建索引的话,又会增加索引的磁盘占用。正因为如此,如果使用了全局查询筛选器,我们就需要根据项目的需要进一步优化数据库。
悲观并发控制
悲观并发控制一般采用行锁、表锁等排他锁对资源进行锁定,确保同时只有一个使用者操作被锁定的资源;乐观并发控制则允许多个使用者同时操作同一个资源,通过冲突的检测避免并发操作。
因为不同类型的数据库对于悲观并发控制的实现差异很大,所以EF Core没有封装悲观并发控制,需要开发人员编写原生SQL语句。
锁是和事务相关的,通过BeginTransactionAsync创建一个事务,并且在所有操作完成后调用CommitAsync提交事务。
对于高并发系统,要尽量优化算法,比如调整逻辑或者使用NoSQL等,尽量避免通过关系数据库进行并发控制。如果必须使用数据库进行并发控制,尽量采用乐观并发控制。
乐观并发控制
EF Core内置了使用并发令牌列实现的乐观并发控制,并发令牌列通常就是被并发操作影响的列。
EF Core中,我们只要把被并发修改的属性使用IsConcurrencyToken设置为并发令牌即可。
乐观并发控制不需要显式地使用事务,而且不需要使用数据库锁,我们只要捕捉保存更改时候的DbUpdateConcurrency-Exception异常即可。我们可以通过DbUpdateConcurrencyException类的Entries属性获取发生并发修改冲突的EntityEntry对象,并且通过EntityEntry类的GetDatabaseValuesAsync获取当前数据库的值
如果有一个确定的字段要被进行并发控制,使用IsConcurrencyToken把这个字段设置为并发令牌即可;如果无法确定唯一的并发令牌列,可以引入一个额外的属性并将其设置为并发令牌,并且在每次更新数据的时候,手动更新这一列的值;
第6章 ASP.NET Core Web API基础
.NET Core中进行Web应用开发的核心底层技术是ASP.NET Core。在ASP.NET Core这个底层基础上,微软开发了ASP.NET Core MVC和ASP.NET Core Web API这两个框架。
ASP.NET Core MVC项目
ASP.NET Core MVC采用MVC模式,也就是把页面交互的代码分为模型(model)、视图(view)和控制器(controller)3个部分。视图负责内容的展现,也就是用来显示HTML(hypertext markup language,超文本标记语言)网页;控制器负责处理用户的请求及为视图准备数据;模型负责在视图和控制器之间传递数据。使用MVC模式的优点是视图和控制器降低了耦合,系统的结构更清晰。
从.NET 6开始,.NET中增加了热重载(hot reload)功能,它允许我们在以调试方式运行程序的时候,也无须重启程序而让修改的代码生效。它的用法很简单,只要在修改完代码以后单击Visual Studio工具栏中的热重载图标,也可以单击热重载图标旁边的下拉按钮,勾选【文件保存时热重载】,这样当我们修改完代码并保存文件后,Visual Studio会自动执行热重载,开发就更方便了。
在我们对项目做结构比较大的改动的时候,比如删除了方法或者修改了方法的参数时,热重载功能就可能无法正常执行,遇到这种情况,我们就必须重启程序。
在开发的时候,作者建议平时使用【启动(不调试)】的方式运行程序,这样在修改完代码后重新生成程序就能让修改的代码生效。
使用ASP.NET Core开发Web API
启动项目,会发现Visual Studio自动启动了浏览器,并且访问了/swagger/index.html这个路径
这是我们创建项目的时候勾选的【启用OpenAPI支持】所启用的Swagger页面,这个页面会根据项目中的接口定义生成一个接口定义浏览的页面。在这个页面中,我们不仅可以查看项目提供了哪些接口,参数和返回值是什么类型的,甚至还可以在页面上进行接口调用的测试。这个页面无论对于接口的开发人员还是接口的使用者,使用起来都非常方便。
每次浏览器重启之后,在Swagger上填写的数据就会消失,我们需要重新填写,这在反复测试接口的时候很麻烦。Postman等第三方工具可以把请求数据保存起来以便反复测试
Restful:想说爱你不容易
Web API开发有两种风格:面向过程的(简称RPC)、面向REST的(简称REST)。
在RPC风格的系统中,URL(uniform resource locator,统一资源定位符)中包含以名词形式描述的资源(比如Persons)和以动词形式描述的动作(比如AddNew)。
在REST风格的Web API中,接口把服务器端当成资源来处理。REST风格的接口按照HTTP设计之初的语义来使用HTTP,把系统中的所有内容都抽象为资源,所有对资源的操作都是无状态的且可以通过标准的HTTP谓词来进行。
HTTP的设计哲学包含以下几个重点内容:
(1)在HTTP中,我们要通过URL进行资源的定位。
(2)在HTTP中,不同的请求方法(又被叫作请求谓词)有不同的含义。
不同谓词有不同的用途,获取资源用GET、新增资源用POST、整体更新(如果不存在则创建)资源用PUT、删除资源用DELETE。
(3)在HTTP中,DELETE、PUT、GET请求应该是幂等的,而POST则不是幂等的。所谓“幂等”指的是:对于一个接口采用同样的参数请求一次和请求多次的结果是一致的,不会因为多次请求而产生副作用。
(4)在HTTP中,GET请求的响应是可以被缓存的,而DELETE、PUT、POST请求的响应是不可以被缓存的。
(5)在HTTP中,服务器端要通过状态码来反映资源获取的结果。
微软为Web API提供的模板代码、示例代码大部分都严格遵守Restful风格,如果把它们改造成RPC风格,需要做如下操作。
(1)控制器上添加的[Route(“[controller]”)]改为[Route(“[controller]/[action]”)],这样[controller]就会匹配控制器的名字,而[action]就会匹配操作方法的名字。
(2)我们强制要求控制器中不同的操作用不同的方法名。
(3)把[HttpGet]、[HttpPost]、[HttpDelete]、[HttpPut]这些Attribute添加到对应的操作方法上。这不仅会帮助接口开发人员明确操作方法接收的请求类型,更能帮助Swagger+OpenAPI生成文档。
如果控制器中存在一个没有添加[HttpGet]、[HttpPost]等的public方法,Swagger就会报错“Failed to load API definition.”,
对于这样的方法,请把[ApiExplorerSettings(IgnoreApi=true)]添加到方法上,从而告知Swagger忽略这个方法。
ASP.NET Core Web API各种技术及选择
一般情况下,我们编写的Web API控制器类继承自ControllerBase即可。
ASP.NET Core Web API中的操作方法的返回值如果是普通数据类型,那么返回值就会默认被序列化为JSON格式的响应报文体返回。
应该使用ActionResult
操作方法的参数从哪里来
我们在给服务器端传递参数的时候,有URL、QueryString、请求报文体3种方式。
我们可以在[HttpGet]、[HttpPost]等Attribute中使用占位符(比如{schoolName})来捕捉路径中的内容,从而供操作方法的参数匹配时使用。
如果占位符的名字和参数名不一致,我们就需要为参数添加[FromRoute],并且通过[FromRoute]的Name属性来设置匹配的占位符的名字。
对于通过QueryString传递的参数,我们使用[FromQuery]来获取值。
如果操作方法的参数的名字和要获取的QueryString的名字不一致,我们就要为设定【FromQuery】的Name属性指定和QueryString中一样的名字。
对于GET、DELETE等请求,我们尽量从URL或者QueryString中获取数据;对于PUT、DELETE等请求,我们尽量通过JSON格式的报文体获取数据,当然我们一定要设定请求报文头中的Content-Type的值为application/json。
跨域
CORS是浏览器中标准的跨域通信的方式,
原理其实很简单,就是在服务器的响应报文头中通过access-control-allow-origin告诉浏览器允许跨域访问的域名。
启用CORS的步骤很简单 参考“在 ASP.NET Core 中启用跨源请求”: (CORS) https://learn.microsoft.com/zh-cn/aspnet/core/security/cors?view=aspnetcore-8.0
第7章 ASP.NET Core基础组件
ASP.NET Core中的依赖注入
ASP.NET Core初始项目模板中,我们通过调用AddControllers方法把项目中的控制器及相关的服务注册到容器中,然后通过调用AddSwaggerGen方法把Swagger相关的服务注册到容器中。当我们需要注册服务的时候,只要把注册代码写到Program.cs的builder.Build之前即可。一般来讲,服务的注册顺序不会影响程序的运行效果,因此我们一般不用关注不同服务注册代码的顺序。
由于控制器是被AddControllers方法注册到容器中的,而且控制器的实例化是由依赖注入框架来负责的,因此在控制器中我们同样可以用依赖注入的方式来使用容器中的服务。
如何实现在执行某个Action的时候才注入特定的服务呢?我们可以把Action用到的服务通过Action的参数注入,然后在这个参数上标注[FromServices]这个Attribute。
当然,作者建议,大部分服务仍然通过控制器的构造方法来注入,只有使用频率不高并且比较消耗资源的服务才通过Action的参数来注入。需要注意的是,只有ASP.NET Core的控制器类的操作方法才能用[FromServices]注入服务,普通的类是不支持这种写法的。
配置系统与ASP.NET Core的集成
ASP.NET Core的多环境设置
为了确定运行时环境,ASP.NET Core会从环境变量中读取名字为ASPNETCORE_ENVIRONMENT的值,这个值就是程序运行环境的名字。ASPNETCORE_ENVIRONMENT的值可以设置为任意值,推荐采用如下3个值:Development(开发环境)、Staging(测试环境)、Production(生产环境)。如果没有设置ASPNETCORE_ENVIRONMENT,则认为程序运行在生产环境。
通过app.Environment.EnvironmentName读取到运行环境的名字,而且ASP.NET Core也提供了IsDevelopment、IsProduction、IsStaging等IHostEnvironment的扩展方法来简化对运行环境的判断。
在测试、开发环境下,我们还可以分别再创建appsettings.Staging.json、appsettings.Production.json文件。一般来讲,我们在appsettings.json中编写开发、测试、生产环境下都共用的配置,然后在appsettings.Development.json等文件中编写开发环境等的特有配置。
用“用户机密”来避免机密信息的泄露
用户机密机制也是一种配置提供器,允许用户把不方便放到appsettings.json中的机密信息放到一个单独的JSON文件中,这个文件不是被放到项目中的,因此不容易被错误地上传到源代码服务器。
用户机密在ASP.NET Core项目中的使用非常简单,只要在ASP.NET Core项目上右击,选择【管理用户机密】,Visual Studio就会在项目的csproj文件中增加一个UserSecretsId节点,这个节点的值就是一个用来定位用户机密配置的标识。Visual Studio还会自动打开一个secrets.json文件,我们在这里按照正常的JSON配置文件的使用方法来配置机密信息即可。
在使用用户机密的时候有如下几点需要注意:
(1)用户机密机制是供开发人员使用的,因此不适合在生产环境中使用。
(2)secrets.json中的配置仍然是明文存储的,并没有加密。如果想避免连接字符串等机密配置被别人看到,可以采用配置服务器。但是无论什么配置服务器,只要程序能读取出这些配置,采用任何配置服务器的“连接字符串加密”只能增加机密信息被发现的难度,不能彻底杜绝机密信息被发现。
(3)如果由于操作系统重装等原因造成secrets.json被删除,我们就需要对其重新配置。
EF Core与ASP.NET Core的集成
分层项目中EF Core的用法
在分层项目中,我们把实体类、上下文写到独立于ASP.NET Core的项目中,把数据库连接的配置使用依赖注入的方式写到ASP.NET Core项目中,这样就做到了项目职责的清晰划分。
上下文被创建的时候不仅要创建数据库连接,而且要执行实体类的配置等,因此实例化上下文的时候会消耗较多的资源。为了避免性能损失,EF Core中提供了可以用来代替AddDbContext的AddDbContextPool来注入上下文。
不过,使用AddDbContextPool时也有一些需要注意的问题。首先,使用AddDbContext的时候,我们可以为上下文注入服务;但是在使用AddDbContextPool的时候,由于上下文实例会被复用,因此我们无法为上下文注入服务。其次,上下文池和数据库连接池的共存如果处理不当就会引起问题。
推荐开发人员采用“小上下文”策略,也就是项目中存在多个上下文类,每个上下文类中只有少数几个实体类。如果项目中采用小上下文策略,并且启用了数据库连接池的话,一般也不需要使用AddDbContextPool。
性能优化“万金油”:缓存
由于从缓存中读取数据的速度比从数据源中读取数据的速度更快,因此使用缓存能提高系统数据的获取速度。如果从缓存中获取了要获取的数据,就叫作“缓存命中”;多次请求中,命中的请求占全部请求的百分比叫作“命中率”;如果数据源中的数据保存到缓存后,发生了变化,就会导致“缓存数据不一致”。
客户端响应缓存
一般不需要手动控制响应报文头中的cache-control,只要给需要进行缓存控制的控制器的操作方法添加ResponseCacheAttribute这个Attribute即可
默认情况下,[ResponseCache]设置只通过生成cache-control响应报文头来控制客户端缓存。如果客户端不支持客户端缓存,这个设置也是不生效的,毕竟是否使用缓存、如何使用缓存都是由客户端决定的,cache-control响应报文头只是一个“建议”而已。
服务器端响应缓存
如果我们在ASP.NET Core中安装了“响应缓存中间件”(response caching middleware),ASP.NET Core不仅会继续根据[ResponseCache]设置来生成cache-control响应报文头以设置客户端缓存,还会在服务器端也按照[ResponseCache]的设置来对响应进行服务器端缓存。
启用响应缓存中间件的步骤很简单,除了给控制器中需要进行缓存控制的操作方法标注[ResponseCache]之外,我们只要在ASP.NET Core项目的Program.cs的app.MapControllers之前加上app.UseResponseCaching即可。注意,如果项目启用了CORS,请确保app.UseCors写到app.UseResponseCaching之前。
在Chrome等浏览器中,当我们禁用浏览器缓存以后,不仅浏览器本地会忽略cache-control而禁用所有客户端缓存,而且浏览器还会在向服务器端发送请求的时候,在请求的报文头中加入“cache-control: no-cache”,
这个报文头用来告知服务器禁用缓存,这样服务器端的缓存机制也会被禁用。这是RFC 7234规范要求的,ASP.NET Core作为大公司开发的Web框架,也要严格遵守这个规范,这也就是浏览器端禁用缓存之后,服务器端响应缓存也失效的原因。
服务器端响应缓存还有很多限制,包括但不限于:响应状态码为200的GET或者HEAD响应才可能被缓存;报文头中不能含有Authorization、Set-Cookie。服务器端响应缓存的使用也比较复杂,如果设置不当的话,会导致缓存的数据错误。
由于服务器端响应缓存开发调试的麻烦及过于苛刻的限制,因此除非开发人员能够灵活掌握并应用它,否则作者不建议启用“响应缓存中间件”。
内存缓存
内存缓存的数据保存在当前运行的网站程序的内存中,是和进程相关的。
对于ASP.NET Core MVC项目,框架会自动地注入内存缓存服务;对于ASP.NET Core Web API等没有自动注入内存缓存服务的项目,我们需要在Program.cs的builder.Build之前添加builder.Services.AddMemoryCache来把内存缓存相关服务注册到依赖注入容器中。在使用内存缓存的时候,我们主要使用IMemoryCache接口
对于这种无法接受缓存延时的系统,如果对应的从数据源获取数据的频率不高的话,可以不用缓存;如果我们需要用缓存提升性能的话,可以通过其他机制获取数据源改变的消息,再通过代码调用IMemoryCache的Set方法更新缓存。
缓存穿透问题的规避
缓存穿透是由于“查询不到的数据用null表示”导致的,因此解决的思路也很简单,就是我们把“查不到”也当成数据放入缓存。在日常开发中只要使用GetOrCreateAsync方法即可,因为这个方法会把null也当成合法的缓存值,这样就可以轻松规避缓存穿透的问题了
缓存雪崩问题的规避
比如为了提升网站的运行速度,我们会对数据进行“预热”,也就是在网站启动的时候把一部分数据从数据库中读取出来并加入缓存。如果这些数据设置的过期时间都相同,到了过期时间的时候,缓存项会集中过期,因此又会导致大量的数据库请求,这样数据库服务器就会出现周期性的压力,这种陡增的压力甚至会把数据库服务器“压垮”(崩溃),当数据库服务器从崩溃中恢复后,这些压力又压了过来,从而造成数据库服务器反复崩溃、恢复,这就是数据库服务器的“雪崩”。
解决这个问题的思路也很简单,那就是写缓存时,在基础过期时间之上,再加一个随机的过期时间,这样缓存项的过期时间就会均匀地分布在一个时间段内,就不会出现缓存集中一个时间点全部过期的情况了。
缓存数据混乱的规避
解决这种问题的核心就是要合理设置缓存的ID
分布式缓存
在分布式系统中,如果内存缓存不能满足要求的话,我们就需要把缓存数据保存到专门的缓存服务器中,所有的Web应用都通过缓存服务器进行缓存数据的写入和获取,这样的缓存服务器就叫作分布式缓存服务器。
常用的分布式缓存服务器有Redis、Memcached等。
NET Core中提供了统一的分布式缓存服务器的操作接口IDistributedCache。IDistributedCache同样支持绝对过期时间和滑动过期时间,分布式缓存中提供了DistributedCacheEntryOptions类用来配置过期时间。
IDistributedCache统一规定缓存键的类型为string,缓存值的类型为byte[]。
连接的缓存服务器是Redis,需要通过NuGet安装Microsoft.Extensions.Caching.StackExchangeRedis。
Redis是一个键值对数据库,如果键命名不当,容易造成键名称冲突,从而导致数据混乱。因为Redis服务器可能也在被其他程序使用,为了避免这里缓存的键值对和其他数据混淆,建议为缓存设置一个前缀。
筛选器
ASP.NET Core中的筛选器有以下5种类型:授权筛选器、资源筛选器、操作筛选器、异常筛选器和结果筛选器。
异步异常筛选器要实现IAsyncExceptionFilter接口。由于筛选器中需要把异常信息记录到日志中并且判断程序的执行环境,因此筛选器需要注入ILogger和IHostEnvironment这两个服务。
需要注意的是,只有ASP.NET Core线程中的未处理异常才会被异常筛选器处理,后台线程中的异常不会被异常筛选器处理。
中间件
广义上来讲,中间件指的是系统软件和应用软件之间连接的软件,以便于软件之间的沟通,比如Web服务器、Redis服务器等都可以称作中间件。狭义上来讲,ASP.NET Core中的中间件则指ASP.NET Core中的一个组件。每个中间件由前逻辑、next、后逻辑3部分组成,前逻辑为第一段要执行的逻辑代码,next为指向下一个中间件的调用,后逻辑为从下一个中间件返回所执行的逻辑代码。每个HTTP请求都要经历一系列中间件的处理,每个中间件对请求进行特定的处理后,再将其转到下一个中间件,最终的业务逻辑代码执行完成后,响应的内容也会按照请求处理的相反顺序进行处理,然后形成HTTP响应报文返回给客户端。
这些中间件组成一个管道(pipeline),整个ASP.NET Core的执行过程就是HTTP请求和响应按照中间件组装的顺序在中间件之间流转的过程。
筛选器与中间件的区别
中间件和筛选器所处的层级是不同的,中间件是一个基础的概念,而筛选器是MVC中间件中的机制。所以,中间件可以处理所有的请求,无论是针对控制器的请求还是针对静态文件等的请求,而筛选器只能处理对控制器的请求;由于中间件运行在一个更底层、更抽象的级别,因此在中间件中无法处理IActionResult、ActionDescriptor等MVC中间件特有的概念。
总之,在开发一个对请求进行前后逻辑编程的组件的时候,优先选择使用中间件;但是如果这个组件只针对MVC或者需要调用一些与MVC相关的类的时候,就只能选择筛选器。
第8章 ASP.NET Core高级组件
Authentication与Authorization
针对资源的访问限制有两个概念:Authentication、Authorization。Authentication可以翻译为“鉴权”或者“验证”,它用来对访问者的用户身份进行验证;Authorization可以翻译为“授权”,它用来验证访问者的用户身份是否有对资源进行访问的权限。
标识框架
ASP.NET Core提供了标识(identity)框架,它采用RBAC(role-based access control,基于角色的访问控制)策略,内置了对用户、角色等表的管理及相关的接口,从而简化了系统的开发。标识框架还提供了对外部登录(比如QQ登录、微信登录、微软账户登录等)的支持。
标识框架中提供了IdentityUser
通过NuGet安装Microsoft.AspNetCore.Identity.EntityFrameworkCore。
代替Session(会话)的JWT
JWT和Session的比较
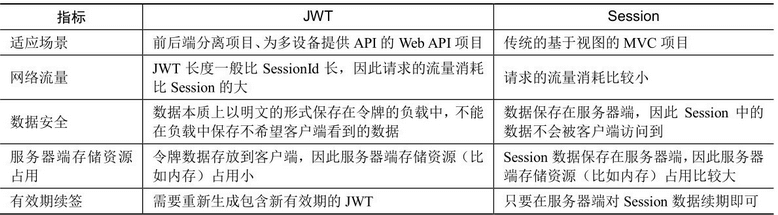
JWT全称是JSON web token,从名字中可以看出,JWT是使用JSON格式来保存令牌信息的。JWT机制不是把用户的登录信息保存在服务器端,而是把登录信息(也叫作令牌)保存在客户端。为了防止客户端的数据造假,保存在客户端的令牌经过了签名处理,而签名的密钥只有服务器端才知道,每次服务器端收到客户端提交的令牌的时候都要检查一下签名,如果发现数据被篡改,则拒绝接收客户端提交的令牌。
JWT的头部(header)中保存的是加密算法的说明,负载(payload)中保存的是用户的ID、用户名、角色等信息,签名(signature)是根据头部和负载一起算出来的值。
在JWT机制下,登录用户的信息保存在客户端,服务器端不需要保存数据,这样我们的程序就天然地适合分布式的集群环境,而且服务器端从客户端请求中就可以获取当前登录用户的信息,不需要再去状态服务器中获取,因此程序的运行效率更高。虽然用户信息保存在客户端,但是由于有签名的存在,客户端无法篡改这些用户信息,因此可以保证客户端提交的JWT的可信度。
程序读取JWT。.NET中进行JWT读写的NuGet包是System.IdentityModel.Tokens.Jwt。
JWT的头部中本质上以明文的形式记录了JWT的签名使用的哈希算法,负载中本质上也以明文的形式记录了我们设置的多条Claim信息。由于JWT会被发送到客户端,而负载中的内容是以明文形式保存的,因此一定不要把不能被客户端知道的信息放到负载中。
JWT的编码和解码规则都是公开的,而且负载部分的Claim信息也是明文的,因此恶意攻击者可以对负载部分中的用户ID等信息进行修改,从而冒充其他用户的身份来访问服务器上的资源。因此,服务器端需要对签名部分进行校验,从而检查JWT是否被篡改了。
我们可以调用JwtSecurityTokenHandler类对JWT进行解码,因为它会在对JWT解码前对签名进行校验
JWT的负载部分还有一个名字为exp的值,它就是我们在生成JWT时设置的过期时间。ValidateToken方法默认也会校验这个过期时间,如果服务器端收到了过期的JWT,即使签名校验成功,ValidateToken方法也会抛出异常。
[Authorize]的注意事项
[Authorize]这个Attribute既可以被添加到控制器类上,也可以被添加到操作方法上。
在控制器类上标注[Authorize],那么这个控制器类中的所有操作方法都会被进行身份验证和授权验证;对于标注了[Authorize]的控制器类,如果其中某个操作方法不想被验证,我们可以在这个操作方法上添加[AllowAnonymous]。
在发送请求的时候,我们只要按照HTTP的要求,把JWT按照“Bearer JWT”格式放到名字为Authorization的请求报文头中即可。ASP.NET Core会按照HTTP的规范,从Authorization中取出令牌,并且进行校验、解析,然后把解析结果填充到User属性中,这一切都是ASP.NET Core完成的,不需要开发人员自己编写代码。但是,如果由于设置或者代码错误导致校验失败,服务器端只会给出状态码为401的响应,开发人员很难得知问题到底出在哪里。
解决JWT无法提前撤回的难题
JWT的缺点是:一旦JWT被发放给客户端,在有效期内这个令牌就一直有效,令牌是无法被提前撤回的。
网上有很多解决方案,比如用Redis保存状态,或者用refresh_token+access_token机制等,这些方案各自有相应的优缺点。
分享一个作者摸索出来的能够满足常规需求的解决方案:在用户表中增加一个整数类型的列JWTVersion,它代表最后一次发放出去的令牌的版本号;每次登录、发放令牌的时候,我们都让JWTVersion的值自增,同时将JWTVersion的值也放到JWT的负载中;当执行禁用用户、撤回用户的令牌等操作的时候,我们让这个用户对应的JWTVersion的值自增;当服务器端收到客户端提交的JWT后,先把JWT中的JWTVersion值和数据库中的JWTVersion值做比较,如果JWT中JWTVersion的值小于数据库中JWTVersion的值,就说明这个JWT过期了,这样我们就实现了JWT的撤回机制。由于我们在用户表中保存了JWTVersion值,因此这种方案本质上仍然是在服务器端保存状态,这是绕不过去的,只不过这种方案是一种缺点比较少的妥协方案。
利用托管服务执行后台代码
ASP.NET Core中提供了托管服务(hosted service)来供我们编写运行在后台的代码。
一般情况下我们编写从BackgroundService类继承的类,因为BackgroundService实现了IHostedService接口,并且帮我们处理了任务的取消等逻辑。我们只要实现BackgroundService类中定义的抽象方法ExecuteAsync,在ExecuteAsync方法中编写后台执行的代码即可。BackgroundService类实现了IDisposable接口,我们可以把任务结束后的清理代码写到Dispose方法中。
为了让托管服务能够运行,我们需要在Program.cs中调用AddHostedService方法把它注册到依赖注入容器中。
托管服务会随着应用程序启动,当然,托管服务是在后台运行的,不会阻塞ASP.NET Core中其他程序的运行。
从.NET 6开始,当托管服务中发生未处理异常的时候,程序就会自动停止并退出。我们可以把HostOptions.BackgroundServiceExceptionBehavior设置为Ignore,这样当托管服务中发生未处理异常的时候,程序会忽略这个异常,而不是停止程序。不过推荐读者还是采用默认的设置,因为未处理异常应该被妥善处理,而不是被忽略。
为了避免托管服务中出现未处理异常导致程序退出,我们要先做好预防工作,在代码中尽量避免异常的产生。
开发人员在完善托管服务的代码的同时,也要在ExecuteAsync方法中把代码用try…catch“包裹”起来,当发生异常的时候,我们把异常记录到日志中或者通过报警系统发送给管理员,这样不仅不会因为托管服务中的未处理异常导致程序的退出,我们也能把托管服务中的运行错误告知管理员。
托管服务中使用依赖注入的陷阱:
托管服务是以单例的生命周期注册到依赖注入容器中的。按照依赖注入容器的要求,长生命周期的服务不能依赖短生命周期的服务,因此我们可以在托管服务中通过构造方法注入其他生命周期为单例的服务,但是不能注入生命周期为范围或者瞬态的服务。
我们可以通过构造方法注入IServiceScopeFactory服务,它可以用来创建IServiceScope对象,这样我们就可以通过IServiceScope来创建短生命周期的服务了
请求数据的校验
.NET Core内置的校验机制有以下几个问题。
- 无论是通过在属性上标注校验规则Attribute的方式,还是实现IValidatableObject接口的方式,我们的校验规则都是和模型类耦合在一起的,这违反了面向对象的“单一职责原则”。
- .NET Core中内置的校验规则不够多,很多常用的校验需求都需要我们编写自定义校验规则。
FluentValidation的基本使用
数据校验框架—FluentValidation,它可以让我们用类似于EF Core中Fluent API的方式进行校验规则的配置,也就是我们可以把对模型类的校验放到单独的校验类中。安装NuGet包FluentValidation.AspNetCore
在编写数据校验代码的时候,有时候我们需要调用依赖注入容器中的服务,FluentValidation中的数据校验类是通过依赖注入容器实例化的,因此我们同样可以通过构造方法来向数据校验类中注入服务。
SignalR服务器端消息推送
ASP.NET Core SignalR(以下简称SignalR)是.NET Core平台中对WebSocket的封装,从而让开发人员可以更简单地进行WebSocket开发。
SignalR中一个重要的组件是集线器(hub),它用于在WebSocket服务器端和所有客户端之间进行数据交换,所有连接到同一个集线器上的程序都可以互相通信。
前端项目中安装SignalR的JavaScript客户端SDK(software development kit,软件开发工具包):npm install @microsoft/signalr。
在SignalR的JavaScript客户端中,我们使用HubConnectionBuilder来创建从客户端到服务器端的连接;通过withUrl方法来设置服务器端集线器的地址,该地址必须是包含域名等的全路径,必须和在服务器端MapHub设置的路径一致;通过withAutomaticReconnect设置自动重连机制。
对HubConnectionBuilder设置完成后,我们调用build就可以构建完成一个客户端到集线器的连接。我们通过build获得的到集线器的连接只是逻辑上的连接,还需要调用start方法来实际启动连接。一旦连接建立完成,我们就可以通过连接对象的invoke函数来调用集线器中的方法,我们也可以通过on函数来注册监听服务器端使用SendAsync发送的消息的代码。
协议协商
SignalR其实并不只是对WebSocket的封装,它支持多种服务器推送的实现方式,包括WebSocket、服务器发送事件(server-sent events)和长轮询。SignalR的JavaScript客户端会先尝试用WebSocket连接服务器;如果失败了,它再用服务器发送事件方式连接服务器;如果又失败了,它再用长轮询方式连接服务器。因此SignalR会自适应复杂的客户端、网络、服务器环境来支持服务器端推送的实现。
SignalR的JavaScript客户端和服务器之间会首先进行一次“协商”,确定采用什么协议进行通信,这个协商过程我们有时候也称之为“握手”。协商完成后,客户端和服务器之间再建立WebSocket通信。在协商的时候,服务器端就会为这个客户端后面的连接创建一些上下文信息,在建立WebSocket连接的时候就会使用服务器端创建的那些上下文信息,也就是说服务器端会在协商请求和WebSocket请求之间保持状态。
解决SignalR在多台服务器组成的集群中的这个问题,有两个方法:黏性会话和禁用协商。
黏性会话(sticky session)指的是,我们对负载均衡服务器进行配置,以便把来自同一个客户端的请求都转发给同一台服务器。
禁用协商的解决策略很简单,就是SignalR客户端不和服务器端进行网络协议的协商,而直接向服务器发出WebSocket请求。由于没有协商过程,因此也就没有两次请求状态保持的问题,而且WebSocket连接一旦建立后,在客户端和服务器端直接就建立了持续的网络连接通道,在WebSocket连接中的后续往返WebSocket通信都由同一台服务器来处理。这种方法的缺点就是对于不支持WebSocket的浏览器无法降级到服务器发送事件或长轮询的实现方式,不过这不是什么大问题,因为现在主流浏览器都支持WebSocket。在移动端,只有Android 4.0以下内置浏览器才不支持WebSocket,而这样老版本的设备在市场上已经很难见到了。在桌面端,只有IE9及以下浏览器才不支持WebSocket,不过SignalR的JavaScript客户端已经不支持IE全线产品了,因此如果读者的网站需要兼容IE,请不要使用SignalR。
禁用协商的使用方式很简单,我们只要在SignalR的JavaScript客户端的withUrl函数中设置选项即可,
设置的skipNegotiation:true选项表示“跳过协商”,而transport选项表示强制采用的通信方式,我们这里把通信方式强制设置为WebSocket。
SignalR分布式部署
让多台服务器上的集线器连接到一个消息队列中,通过这个消息队列完成跨服务器的消息投递。
微软官方提供了用Redis服务器来解决SignalR部署在分布式环境中数据同步的方案—Redis backplane。
NuGet安装Microsoft.AspNetCore.SignalR.StackExchangeRedis。AddStackExchangeRedis方法的第一个参数为Redis服务器的连接字符串;如果有多个SignalR应用程序连接同一台Redis服务器,那么我们需要为每一个应用程序配置唯一的ChannelPrefix。
SignalR身份认证
SignalR支持验证和授权机制,我们同样可以用Cookie、JWT等方式进行身份信息的传递。NuGet安装Microsoft.AspNetCore.Authentication.JwtBearer。
在ASP.NET Core Web中,我们把JWT放到名字为Authorization的报文头中,但是WebSocket不支持Authorization报文头,而且WebSocket中也不能自定义请求报文头。我们可以把JWT放到请求的URL中,然后在服务器端检测到请求的URL中有JWT,并且请求路径是针对集线器的,我们就把URL请求中的JWT取出来赋值给context.Token,接下来ASP.NET Core就能识别、解析这个JWT了。
在我们进行客户端筛选的时候,有3个筛选参数:ConnectionId、组和用户ID。ConnectionId是SignalR为每个连接分配的唯一标识,我们可以通过集线器的Context属性中的ConnectionId属性获取当前连接的ConnectionId;每个组有唯一的名字,对于连接到同一个集线器中的客户端,我们可以把它们分组;用户ID是登录用户的ID,它对应的是类型为ClaimTypes.NameIdentifier的Claim的值,如果使用用户ID进行筛选,我们需要在客户端登录的时候设定类型为ClaimTypes.NameIdentifier的Claim。
如果我们的系统需要实现接收离线期间的消息的功能,就需要再自行额外开发消息的持久化功能。
在Hub类之外,我们可以通过注入IHubContext< THub>来获取对集线器进行操作的服务,其中泛型THub为要操作的Hub类。
Hub类的生命周期是瞬态的,也就是每次调用集线器的时候都会创建一个新的Hub类实例,因此我们不要在Hub类中通过属性、成员变量等方式保存状态。如果服务器的压力比较大,作者建议把ASP.NET Core程序和SignalR服务器端部署到不同的服务器上,以免它们互相干扰。
ASP.NET Core系统的部署
在发布一个ASP.NET Core网站的时候,我们有两种部署模式可供选择,分别是“框架依赖”和“独立”。在框架依赖模式下,我们发布生成的程序集中不包含.NET运行时,所以我们需要在服务器上安装对应版本的.NET运行时;在独立模式下,我们发布生成的程序集中嵌入了.NET运行时,所以我们不需要在服务器上安装.NET运行时。
独立模式唯一的缺点就是生成的程序包比框架依赖的大,毕竟独立模式把.NET运行时打包到了程序包中,但是利大于弊。在独立模式下,我们需要在程序包中包含.NET运行时,虽然.NET程序集是跨平台的,但是由于.NET运行时需要和操作系统打交道,因此不同操作系统下的.NET运行时有一定的差异性,在用独立模式部署的时候,我们需要选择目标操作系统和CPU类型。
根据项目的规模及计算机的配置不同,发布的耗时也不同,一般至少也要几十秒,所以启动发布流程之后请耐心等待。项目发布完成后,我们只要把发布目录下生成的DLL等全部文件复制到服务器的操作系统上就可以了。
ASP.NET Core内置的Kestrel就是一个跨平台、功能丰富、性能强大的Web服务器,尽管Kestrel已经强大到足以作为一个独立的Web服务器使用了,但是在比较复杂的项目中,我们仍然不会让Kestrel直接面对终端用户的请求,而是在应用程序和用户之间部署负载均衡服务器。
一,推荐的部署方式
如果公司有比较好的运维能力,并且系统的复杂度比较高,那么作者建议采用Linux作为服务器的操作系统,并且采用容器化部署,让应用程序运行在容器中,用Kubernetes进行容器的管理,这种做法是目前行业的推荐做法,也符合.NET Core的设计初衷。
二,HTTPS证书等配置
对于采用了负载均衡服务器的部署方式来讲,我们一般把证书配置在负载均衡服务器上。由于HTTPS通信要进行加密和解密,因此启用HTTPS之后网站的内存、CPU压力会增大,如果负载均衡服务器到网站应用程序之间的通信是安全可信的,那么我们在网站应用程序中就不启用HTTPS了,也就是用户到负载均衡服务器是HTTPS通信,而负载均衡服务器到网站应用程序的Kestrel之间是HTTP通信。如果我们配置了负载均衡服务器到网站应用程序之间采用HTTP通信,那么一定要删掉Program.cs中的UseHttpsRedirection,以避免程序把HTTP请求重定向到HTTPS请求。
三,如何获取客户端的IP地址
对于启用了负载均衡服务器的网站来讲,由于用户的请求由负载均衡服务器转发给网站应用程序,因此在网站应用程序看来,请求是负载均衡服务器发出的,我们在使用HttpContext.Connection.RemoteIpAddress获取客户端的IP地址的时候,获取的其实是负载均衡服务器地址,而非原始的用户IP地址。
大部分负载均衡服务器都支持开启把原始的用户IP地址放到名字为X-Forwarded-For的请求报文头中的设置。
一定要注意X-Forwarded-For造假的问题。防范这种问题的手段有两点需要注意:如果网站应用程序直接面对用户请求,而没有使用负载均衡服务器的话,就不要启用ForwardedHeadersMiddleware中间件;在面向最终用户的负载均衡服务器上,请设置忽略客户端请求报文头中的X-Forwarded-For。
四,程序的更新
无论是app_offline.htm还是影子拷贝,它们都只能在IIS中部署网站时使用。如果我们使用容器+负载均衡服务器的方式来部署网站,只要启动新版网站的容器,然后把旧版网站的容器停止就可以了。
我们在编写新版系统的时候,要考虑规避这样的短时间内新旧版程序共存导致的逻辑混乱的问题。
五,如何构建一个安全的系统
从开发人员的角度来谈一下需要注意的一些事项。网站一定要启用HTTPS,从而避免网站内容被运营商劫持,以及避免网站通信被窃听。
Web服务器一定要只开放Web服务的端口,其他端口不要开放。
要启用负载均衡服务器。
要启用WAF(Web application firewall,Web应用程序防火墙),WAF可以阻挡相当一部分潜在的网络攻击。
数据库服务器只允许Web服务器的IP地址访问;数据库服务器一定要设置定时自动备份机制,并且把备份文件异地保存,以便在出现问题时及时恢复数据。
严格区分开发环境和生产环境,增强生产环境的访问权限管理,避免开发人员直接访问生产环境的服务器。对开发人员的代码进行审查,特别要防范CSRF(cross-site request forgery,跨站请求伪造)、XSS(cross site scripting,跨站脚本攻击)、SQL注入漏洞、请求重放攻击等。不要相信客户端提交的任何数据,要对客户端提交的数据进行校验,因为客户端提交的数据有可能是造假的。
防范关键业务数据的“可预测性”。
这个问题的解决方案就是用Guid等不可预测的值作为主键值。
避免服务器端发送给客户端的报错信息造成的泄密,尽量不要把服务器内部的细节发送给客户端。
第9章 DDD实战
DDD(domain-driven design,领域驱动设计)是设计一个优秀的微服务架构的指导思想。
架构设计的术与道
做架构设计的时候,一定要分析行业情况、公司情况、公司未来发展、项目情况、团队情况等来设计适合自己的架构,不能盲目跟风。
我们只要基于成熟的技术进行开发,并且对项目未来较短一段时间内的发展进行预测,在项目架构上做必要的准备就可以了,没必要“想得太长远”。架构设计在满足必要的可扩展性、隔离性的基础上,要尽可能简单。
可以持续升级的架构,叫作“演进式架构”。一个好的软件架构应该是可以防止软件退化的。软件退化指的是在软件升级的时候,随着功能的增加和系统复杂度的提升,代码的质量越来越差,系统的稳定性和可维护性等指标越来越差。软件的需求是不断变更的,软件的升级也是必然的,因此我们应该在进行架构设计的时候避免后续软件需求变更导致软件退化,并且在软件的升级过程中,我们要适时地进行架构的升级,以保持高质量的软件设计。
9.2 DDD的基本概念
传统的软件项目大部分都是单体结构,也就是项目中的所有代码都放到同一个应用程序中,一般它们也都运行在同一个进程中。
什么是微服务
单体结构的项目有结构简单、部署简单等优点,但是有如下的缺点。
- 代码之间耦合严重,代码的可维护性低。
- 项目只能采用单一的语言和技术栈,甚至采用的开发包的版本都必须统一。
- 一个模块的崩溃就会导致整个项目的崩溃。
- 我们只能整体进行服务器扩容,无法对其中一个模块进行单独的服务器扩容。
当需要更新某一个功能时,我们需要把整个系统重新部署一遍,这会导致新功能的上线流程变长。微服务架构把项目拆分为多个应用程序,每个应用程序单独构建和部署
微服务架构有如下的优点。
- 每个微服务只负责一个特定的业务,业务逻辑清晰、代码简单,对于其他微服务的依赖非常低,因此易于开发和维护。
- 不同的微服务可以用不同的语言和技术栈开发。
- 一个微服务的运行不会影响其他微服务。
- 可以对一个特定的微服务进行单独扩容。
当需要更新某一个功能的时候,我们只需要重新部署这个功能所在的微服务即可,不需要重新部署整个系统。
微服务架构的缺点如下。
- 在单体结构中,运维人员只需要保证一个应用的正常运行即可,而在微服务架构中,运维人员需要保证多个应用的正常运行,这给运维工作带来了更大的挑战。
- 在单体结构中,各模块之间是进程内调用,数据交互的效率高,而在微服务架构中,各微服务之间要通过网络进行通信,数据交互的效率低。
- 在单体结构中,各模块之间的调用都是在进程内进行的,实现容错、事务一致性等比较容易,而在微服务架构中,各微服务之间通过网络通信,实现容错、事务一致性等非常困难。
微服务架构的误区
在应用微服务架构的时候,我们可能会有微服务切分过细和微服务之间互相调用过于复杂这两个主要的误区。
DDD为什么难学
DDD的英文全称是domain driven design,翻译成中文就是“领域驱动设计”。
领域其实指的就是业务,因此DDD其实就是一种用业务驱动的设计。
DDD的核心理念就是所有人员站在用户的角度、业务的角度去思考问题,而不是站在技术的角度去思考问题。
确定一个领域之后,我们就要对领域内的对象进行建模,从而抽象出模型的概念,这些领域中的模型就叫作领域模型(domain model)。
使用DDD,我们在分析完产品需求后,就应该创建领域模型,而不是考虑如何设计数据库和编写代码。使用领域模型,我们可以一直用业务语言去描述和构建系统,而不是使用技术人员的语言。
通用语言与界限上下文
在进行系统开发的时候,非常容易导致歧义的是不同人员对于同一个概念的不同描述。
在描述业务对象的时候,拥有确切含义的、没有二义性的语言是非常重要的,这样的语言就是“通用语言”。在应用DDD的时候,团队成员必须对于系统内的每一个业务对象有确定的、无二义性的、公认的定义。通用语言离不开特定的语义环境,只有确定了通用语言所在的边界,才能没有歧义地描述一个业务对象。
界限上下文就是用来确定通用语言的边界的,在一个特定的界限上下文中,通用语言有着唯一的含义。
实体类与值对象
在具体实现DDD的时候,实体类一般的表现形式就是EF Core中的实体类,实体类的Id属性一般就是标识符,Id属性的值不会变化,它标识着唯一的对象,实体类的其他属性则可能在运行时被修改,但是只要Id不变,我们就知道前后两个对象指的是同一个对象。我们可以把实体类的对象保存到数据库中,也可以把它从数据库中读取出来。
在DDD中还存在着一些没有标识符的对象,它们也有多个属性,它们依附于某个实体类对象而存在,这些没有标识符的对象叫作值对象。
值对象一般是不可变的,也就是值对象的属性不可以修改。因此如果我们要修改实体类中的一个值对象属性,我们只能创建一个新的值对象来替换旧的值对象。
实体类帮助我们跟踪对象的变更,而值对象则帮助我们把多个相关属性当作一个整体。
聚合与聚合根
把关系紧密的实体类放到一个聚合(aggregate)中,每个聚合中有一个实体类作为聚合根(aggregate root),所有对聚合内实体类的访问都通过聚合根进行,外部系统只能持有对聚合根的引用,聚合根不仅仅是实体类,还是所在聚合的管理者。
聚合并不是简单地把实体类组合在一起,而要协调聚合内若干实体类的工作,让它们按照统一的业务规则运行,从而实现实体类数据访问的一致性,这样我们就能够实现聚合内的“高内聚”;聚合之间的关系很弱,一个聚合只能引用另外一个聚合的聚合根,这样我们就能够实现聚合间的“低耦合”。
小聚合有助于进行微服务的拆分,也有助于减少数据修改冲突。设计聚合的一个原则就是:聚合宁愿设计得小一点儿,也不要设计得太大。
领域服务与应用服务
对于聚合内的业务逻辑,我们编写领域服务(domain service),而对于跨聚合协作的逻辑,我们编写应用服务(application service)。应用服务协调多个领域服务来完成一个用例。
需要注意的是,领域服务不是必需的,在一些简单的业务处理(比如增、删、改、查)中是没有领域知识(也就是业务逻辑)的,这种情况下应用服务可以完成所有操作,不需要引入领域服务,这样我们可以避免系统出现过度设计的问题。如果随着系统的进化,应用服务中出现了业务逻辑,我们就要把业务逻辑放入领域服务。
和聚合相关的两个概念是“仓储”(repository)和“工作单元”(unit of work)。
实体类负责业务逻辑的处理,仓储负责按照要求从数据库中读取数据以及把领域服务修改的数据保存回数据库,一个聚合对应一个用来实现数据持久化的仓储。
聚合内的若干相关联的操作组成一个“工作单元”,这些工作单元要么全部成功,要么全部失败。
因为领域服务不依赖外部系统、不保存状态,所以领域服务比应用服务更容易进行单元测试,这对于提高系统的质量是非常有帮助的。
领域事件与集成事件
面向对象设计中有一个原则是“开闭原则”,即“对扩展开放,对修改关闭”,通俗来讲就是“当需要增加新的功能的时候,我们可以通过增加扩展代码来完成,而不需要修改现有的代码”。
DDD中的事件分为两种类型:领域事件(domain events)和集成事件(integration events)。
领域事件主要用于在同一个微服务内的聚合之间的事件传递,而集成事件用于跨微服务的事件传递。
领域事件由于是在同一个进程内进行的,我们通过进程内的通信机制就可以完成;集成事件由于需要跨微服务进行通信,我们就要引入事件总线(eventbus)来实现事件的传递。我们一般使用消息队列服务器中的“发布/订阅”模式来实现事件总线。
DDD的技术落地
在面向对象的设计中有贫血模型和充血模型两种风格。所谓的贫血模型指的是一个类中只有属性或者成员变量,没有方法,而充血模型指的是一个类中既有属性、成员变量,也有方法。
采用充血模型编写代码,我们能更好地实现DDD和模型驱动编程。
EF Core对实体类属性操作的秘密
EF Core在读写实体类对象的属性时,会查找类中是否有与属性的名字一样(忽略大小写)的成员变量,如果有这样的成员变量的话,EF Core会直接读写这个成员变量的值,而不是通过set和get代码块来读写。
EF Core中实现充血模型
充血模型中的实体类和POCO类相比,有如下的特征。特征一:属性是只读的或者只能被类内部的代码修改。特征二:定义了有参构造方法。特征三:有的成员变量没有对应属性,但是这些成员变量需要映射为数据库表中的列,也就是我们需要把私有成员变量映射到数据库表中的列。特征四:有的属性是只读的,也就是它的值是从数据库中读取出来的,但是我们不能修改属性值。特征五:有的属性不需要映射到数据列,仅在运行时被使用。
EF Core中实现值对象
EF Core中提供了对于没有标识符的值对象进行映射的功能,那就是“从属实体类”(owned entities)类型,我们只要在主实体类中声明从属实体类型的属性,然后使用Fluent API中的OwnsOne等方法来配置。
EF Core中可以在Fluent API中用
HasConversion<string>把枚举类型的值配置成字符串。千万不要面向数据库建模
在进行领域模型建模的时候,不考虑数据库,而是最后使用Fluent API来处理数据库实现的细节。
当然,受制于技术条件,有一些领域模型中的设计我们无法实现,这种情况下,我们可以稍微妥协,修改领域模型中的设计,以便这个设计能够实现,但是不应该在建模的时候就先考虑具体的实现。
上下文可以从数据库中查询出数据并且跟踪对象状态的改变,然后把对象状态的改变保存到数据库中,因此上下文就是一个天然的仓储的实现;上下文会跟踪多个对象状态的改变,然后在SaveChanges方法中把所有的改变一次性提交到数据库中,这是一个“要么全部成功,要么全部失败”的操作,因此上下文也是一个天然的工作单元的实现。
如果选择了把一个微服务中所有聚合中的实体类都放到同一个上下文中,为了区分聚合根实体类和其他实体类,我们可以定义一个不包含任何成员的标识接口,比如IAggregateRoot,然后要求所有的聚合根实体类都实现这个接口。
用MediatR实现领域事件
领域事件可以切断领域模型之间的强依赖关系,事件发布完成后,由事件的处理者决定如何响应事件,这样我们可以实现事件发布和事件处理之间的解耦。
MediatR是一个在.NET中实现进程内事件传递的开源库,它可以实现事件的发布和事件的处理之间的解耦。MediatR中支持“一个发布者对应一个处理者”和“一个发布者对应多个处理者”两种模式
通过NuGet安装
MediatR.Extensions.Microsoft.DependencyInjection。在项目的Program.cs中调用AddMediatR方法把与MediatR相关的服务注册到依赖注入容器中,AddMediatR方法的参数中一般指定事件处理者所在的若干个程序集。
EF Core中发布领域事件的合适时机
领域事件大部分发生在领域模型的业务逻辑方法上或者领域服务上,我们可以在一个领域事件发生的时候立即调用IMediator的Publish方法来发布领域事件。
实体类中只注册要发布的领域事件,然后在上下文的SaveChanges方法被调用时,我们再发布领域事件。
RabbitMQ的基本使用
和领域事件不同,集成事件用于在微服务间进行事件的传递,因为这是服务器间的通信,所以必须借助于第三方服务器作为事件总线。我们一般使用消息中间件来作为事件总线,目前常用的消息中间件有Redis、RabbitMQ、Kafka、ActiveMQ等。
RabbitMQ中的几个基本概念:
(1)信道(channel):信道是消息的生产者、消费者和服务器之间进行通信的虚拟连接。
因为TCP连接的建立是非常消耗资源的,所以RabbitMQ在TCP连接的基础上构建了虚拟信道。我们尽量重复使用TCP连接,而信道是可以用完就关闭的。
(2)队列(queue):队列是用来进行消息收发的地方,生产者把消息放到队列中,消费者从队列中获取消息。
(3)交换机(exchange):交换机用于把消息路由到一个或者多个队列中。
在集成事件中用到的模式,即routing模式,在这种模式中,生产者把消息发布到交换机中,消息会携带routingKey属性,交换机会根据routingKey的值把消息发送到一个或者多个队列;消费者会从队列中获取消息;交换机和队列都位于RabbitMQ服务器内部。这种模式的优点在于,即使消费者不在线,消费者相关的消息也会被保存到队列中,当消费者上线之后,就可以获取离线期间错过的消息。
安装NuGet包RabbitMQ.Client。RabbitMQ中的消息支持“失败重发”,也就是消费者在接收到消息并处理的过程中,如果消息的处理过程出错导致消息没有被完整处理,队列会再次尝试把这条消息发送给消费者。消费者需要在消息处理成功后调用BasicAck通知队列“消息处理完成”,如果消息处理出错,则需要调用BasicReject通知队列“消息处理出错”。
由于同样一条消息可能会被重复投递,因此我们一定要确保消息处理的代码是幂等的。
整洁架构(洋葱架构)
经典的软件分层架构是三层架构,应用程序分为用户界面层、业务逻辑层、数据访问层
2012年,罗伯特·塞西尔·马丁(Robert Cecil Martin)提出了整洁架构,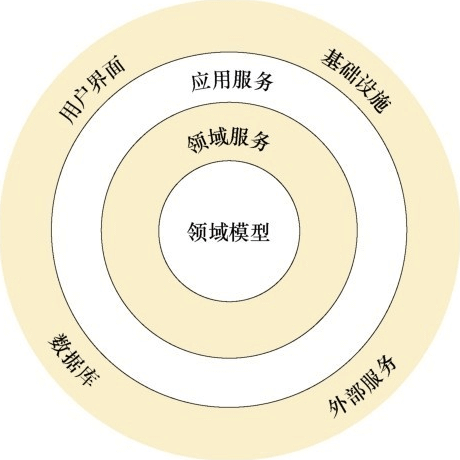
在整洁架构中,不同的同心圆代表软件的不同部分,内层的部分比外层的部分更加抽象,也就是内层表达抽象,外层表达实现。外层的代码只能调用内层的代码,内层的代码可以通过依赖注入的形式来间接调用外层的代码。
整洁架构拥有如下的优点:
- 整洁架构的内层使用领域驱动的思想进行设计,因此架构的抽象程度更高。
- 外层的代码可以调用所有内层的代码,也就是可以跨层直接调用,不需要所有的调用都逐层进行,因此代码更灵活、更简洁。
- 服务的接口定义在内层,服务的实现定义在外层,内层的代码可以通过依赖注入的服务接口的形式调用外层提供的服务,实现了抽象定义和具体实现的分离。
性能优化的原则
如果一味地追求DDD的原则而不追求性能优化,就犯了教条主义错误。软件设计和开发过程中的一切原则都不是不能突破的,解决实际问题是一切原则、技术的出发点。尽管通过DDD模式编写的数据库操作的代码并不是性能最优的,但是只要没有遇到性能瓶颈,我们就不需要采用“手写SQL语句”等方式,以免犯“过早优化”的错误。
开发人员应该对于项目的优化目标进行选择,把精力放到重要的事情上。
要避免在业务层面的代码中进行跨服务的数据库表联合查询。