
《互联网企业安全高级指南-赵彦 江虎 胡乾威》全书涵盖了技术体系、工具平台和流程制度,是一本拓宽视野、入门的书。
业务形态的差异决定了各个企业的安全目标不尽相同。“方向错了,前进便是倒退”。
第1章 安全大环境与背景
视野一定是尽可能的宽泛,是一个“放”字,但落到实践一定是个“收”字,以如今的技术复杂度你不可能样样都精通,只能挑几个。
切入“企业安全”的视角
技术很重要,但攻防只解决了一半问题,安全的工程化以及体系化的安全架构设计能力是业内普遍的软肋,多数人不擅此道。位置决定想法,不是安全不重要,而是有很多事情比安全更重要。老实说,安全这个事情跟金钱关系密切,当你有100万元的时候拿出2万元买个保险箱装它们你觉得值,但你只有2万元的时候要拿出8千元买保险箱,大多数人都会不愿意。在甲方企业高层的眼中,攻防这档子事可以等价于我花点钱让安全公司派几个工程师给我做渗透测试然后修复漏洞,不像大型互联网公司那样上升为系统化和工程化的日常性活动。
企业安全是什么?我认为它可以概括为:从广义的信息安全或狭义的网络安全出发,根据企业自身所处的产业地位、IT总投入能力、商业模式和业务需求为目标,而建立的安全解决方案以及为保证方案实践的有效性而进行的一系列系统化、工程化的日常安全活动的集合。
企业安全包括哪些事情
企业安全涵盖7大领域
1)网络安全
基础、狭义但核心的部分,以计算机(PC、服务器、小型机、BYOD……)和网络为主体的网络安全,主要聚焦在纯技术层面。
2)平台和业务安全
跟所在行业和主营业务相关的安全管理属于特定领域的安全,不算广义安全。
3)广义的信息安全
以IT为核心,包括广义上的“Information”载体:除了计算机数据库以外,还有包括纸质文档、机要,市场战略规划等经营管理信息、客户隐私、内部邮件、会议内容、运营数据、第三方的权益信息等,但凡你想得到的都在其中,加上泛“Technology”的大安全体系。
4)IT风险管理、IT审计&内控
对于中大规模的海外上市公司而言,有诸如SOX-404这样的合规性需求,财务之外就是IT,其中所要求的在流程和技术方面的约束性条款跟信息安全管理重叠,属于外围和相关领域,而信息安全管理本身从属于IT风险管理,是CIO视角下的一个子领域。
5)业务持续性管理
BCM(Business Continuity Management)不属于以上任何范畴,但又跟每一块都有交集,如果你觉得3)和4)有点虚,那么BCM绝对是面向实操的领域。
事实上,BCM提供了另一种更高维度、更完整的视角来看待业务中断的问题。对于安全事件,它的方法论也比单纯的ISMS更具有可操作性,对业务团队更有亲和力,因为你知道任何以安全团队自我为中心的安全建设都难以落地,最终都不会做得很好。
6)安全品牌营销、渠道维护
7)CXO们的其他需求:俗称打杂。
在甲方,安全不是主营业务,归根结底,安全是一个保值型的后台职能,不是一个明显能创造收益的前台职能,是一个成本中心而非盈利中心。
对于互联网公司,我建议做1)、2)、5);对于传统行业,我建议做1)、3)、4)、5)。
在互联网行业,我觉得安全工作可以概括为以下几个方面:
❑ 信息安全管理(设计流程、整体策略等),这部分工作约占总量的10%,比较整体,跨度大,但工作量不多。
❑ 基础架构与网络安全:IDC、生产网络的各种链路和设备、服务器、大量的服务端程序和中间件,数据库等,偏运维侧,跟漏洞扫描、打补丁、ACL、安全配置、网络和主机入侵检测等这些事情相关性比较大,约占不到30%的工作量。
❑ 应用与交付安全:对各BG、事业部、业务线自研的产品进行应用层面的安全评估,代码审计,渗透测试,代码框架的安全功能,应用层的防火墙,应用层的入侵检测等,属于有点“繁琐”的工程,“撇不掉、理还乱”,大部分甲方团队都没有足够的人力去应付产品线交付的数量庞大的代码,没有能力去实践完整的SDL,这部分是当下比较有挑战的安全业务,整体比重大于30%,还在持续增长中。
❑ 业务安全:上面提到的2),包括账号安全、交易风控、征信、反价格爬虫、反作弊、反bot程序、反欺诈、反钓鱼、反垃圾信息、舆情监控(内容信息安全)、防游戏外挂、打击黑色产业链、安全情报等,是在基础安全问题解决之后,越来越受到重视的领域。整体约占30%左右的工作量,有的甚至大过50%。
互联网企业和传统企业在安全建设中的区别
安全领域大部分所谓管理不过是组织技术性的活动而已,充其量叫技术管理。
传统企业安全问题的特征如下:
1)IT资产相对固定。
2)业务变更不频繁。
3)网络边界比较固定。
4)IDC规模不会很大,甚至没有。
5)使用基于传统的资产威胁脆弱性的风险管理方法论加上购买和部署商业安全产品(解决方案)通常可以搞定。
大型互联网企业需要应对如下问题:
❑ 海量IDC和海量数据。
❑ 完全的分布式架构。
❑ 应对业务的频繁发布和变更。
- 传统企业的安全建设
在边界部署硬件防火墙、IPS(入侵防御系统 Intrusion Prevention System 是计算机网络安全设施,是对防病毒软件(antivirus programs)和防火墙的补充。)/IDS(入侵检测系统 Intrusion Detection System 是依照一定的安全策略,对网络、系统的运行状况进行监视,尽可能发现各种攻击企图、攻击行为或者攻击结果,以保证网络系统资源的机密性、完整性和可用性。)、WAF(Web Application Firewall ,Web应用防火墙,区别于传统防火墙,WAF 工作在应用层,主要用于保护Web应用免受各种网络攻击,如SQL注入、XSS跨站脚本、文件包含、命令执行等。)、商业扫描器、堡垒机,在服务器上安装防病毒软件,集成各种设备、终端的安全日志建设SOC,当然购买的安全硬件设备可能远不止这些。在管理手段上比较重视ISMS(信息安全管理体系)的建设,重视制度流程、重视审计,有些行业也必须做等级保护以及满足大量的合规性需求。 - 互联网企业的安全建设
互联网可分为生产网络和办公网络,互联网行业的大部分安全建设都围绕生产网络,而办公网络的安全通常只占整体的较小比重。互联网企业的生产网络中,安全解决方案基本上都是以攻防为驱动的,怕被黑、怕拖库、怕被劫持就是安全建设的最直接的驱动力。 - 从量变到质变
对于超过一定规模的大型互联网公司,其IT建设开始进入自己发明轮子的时代,安全解决方案开始局部或进入全部自研的时代。 - 大型互联网企业安全建设的方法论
自研或对开源软件进行二次开发+无限水平扩展的软件架构+构建于普通中低端硬件之上(PC服务器甚至是白牌)+大数据机器学习的方式,是目前大型互联网公司用来应对业务持续性增长的主流安全解决方案。不止是成本,如果不能做到兼顾宿主的性能,安全架构随整个业务架构水平扩展,保证高可用性,最终安全措施都会走进死胡同。不同规模企业的安全管理
1.创业型公司
安全建设的需求应该是:保障最基本的部分,追求最高性价比,不求大而全。创业公司基本都上公有云了,不会自己再去折腾IDC那点事,所以相对而言以上措施中的一部分可以等价于:
1)使用云平台提供的安全能力,包括各种抗DDoS、WAF、HIDS等。
2)使用市场中第三方安全厂商提供的安全能力。
不过不要因为迷信云平台关于安全能力的广告而自己不再去设防,毕竟针对租户级的通用型的安全方案其覆盖面和防御的维度是有限的。
2.大中型企业
这个层次对应市场上大多数公司的安全需求,它的典型特征是,业务营收的持续性需要安全来保障。这个层级的安全需求没办法很具体地量化。不同的业务模式对应的安全实现还是有很大的不同,加上这个区间里的公司营收规模可以差很大,对应的安全投入也可以差很多。生态级企业vs平台级企业安全建设的需求
从表象上看,生态级公司的大型基础架构如果用传统的安全方案几乎都无法满足,所以会大量的进入自研。而平台级公司则会依赖开源工具更多一些,不会对所有解决方案场景下的安全工具进行自研。
- 差别的成因
第一个因素是技术驱动在底层还是在应用层驱动业务。
平台级公司的安全主要围绕应用层面,而生态级公司的安全会覆盖基础架构和应用层面两块。
很多实际上依靠业务和线下资源驱动而非技术驱动的互联网公司而言,安全建设去做太多高大上的事情显然是没有必要的。
第二个因素是钱,钱也分为两个方面:1)成本;2)ROI。
第三个因素是人。ROI,全称“Return on Investment”,中文叫“投资回报率”,是一种用于衡量投资效益的指标。
ROI的计算公式是:ROI = (收益 - 成本)/ 成本。
云环境下的安全变迁
云计算的本质是改变企业需求方通过传统的渠道获取IT资源的形式。
1.云的租户
对使用云的租户而言,云平台自身以及应用超市Marketplace(类似APP store)集成了各个安全厂商的云安全产品以及可托管的安全专家服务。
2.云安全提供商
相比过去面对面提供安全服务,现在则转变为在租户侧部署各种安全传感器,通过在云端汇聚安全度量数据,结合威胁情报或由专家解读数据来提供可管理的一站式安全服务。
第2章 安全的组织
很多人忽略组织,但实际上组织是比技术和流程更重要的东西,“人”是所有问题的决定性因素。
对绝大多数公司而言,安全建设的需求都是聚焦于应用的,所以安全团队必然也是需要偏网络和应用的人。大牛显然是没必要的,而懂渗透,有一定网络系统应用攻防理论基础的人是最具培养价值的。对于比较大型的平台级公司而言,安全团队会有些规模,不只是需要工程师,还需要有经验的Leader,必须要有在运维安全,PC端Web应用安全以及移动端App安全能独当一面的人,如果业务安全尚有空白地带的话,还需要筹建业务安全团队。
实际上当你进入一个平台级公司开始,安全建设早已不是一项纯技术的工作,而技术管理上的系统性思路会影响整个安全团队的投入产出比。
第3章 甲方安全建设方法论
从零开始
1.三张表
第一张表:组织结构图,这些是开展业务的基础,扫视一下组织结构中每一块安全工作的干系人。
第二张表:每一个线上产品(服务)和交付团队(包括其主要负责人)的映射。
一个安全团队的Leader通常需要对应于一个或若干产品的安全改进。不过这里也要分一下权重,但对于深知大公司病又创业过的我来说,还是稍微有些补充的看法,很多成长中的业务,出于起步阶段,没有庞大的用户群,可能得不到公共职能部门的有力扶持,例如运维、安全等,明日之星的业务完全可能被扼杀在摇篮里,这种时候对有责任心的安全团队来说如何带着VC的眼光选择性的投入是一件很有意思的事。
第三张表:准确地说应该是第三类,包括全网拓扑、各系统的逻辑架构图、物理部署图、各系统间的调用关系、服务治理结构、数据流关系等,这些图未必一开始就有现成的,促成业务团队交付或者自己去调研都可以,以后的日常工作都需要这些基础材料。
2.历史遗留问题
一般情况下都是出了比较严重的安全问题才去招聘安全负责人和建立专职的安全团队的这个问题只能灰度处理,逐步建立入侵检测手段,尝试发现异常行为,然后以类似灰度滚动升级的方式去做一轮线上系统的后门排查。
3.初期三件事
第一件是事前的安全基线,不可能永远做事后的救火队长,所以一定要从源头尽可能保证你到位后新上线的系统是安全的;第二件是建立事中的监控的能力,各种多维度的入侵检测,做到有针对性的、及时的救火;第三件是做好事后的应急响应能力,让应急的时间成本更短,溯源和根因分析的能力更强。
不同阶段的安全建设重点
1.战后重建
第一个阶段是基础的安全建设,这一期主要做生产网络和办公网络的网络安全的基础部分。
就是在前面1.4节“不同规模企业的安全管理”介绍的大中型企业对应的那些需求(当然也包括中小企业的那些)。完成的标志:一方面是所提的那些点全都覆盖到了,另一方面是在实践上不落后于公司的整体技术步伐,比如运维侧在用Puppet、SaltStack之类的工具实现了一定程度的自动化运维,那你的安全措施也不好意思是纯手工。
2.进阶
第二阶段就是要向更广的方向拓展。一是广义的信息安全,其实这个时候你可以把ISO27001(ISO27001是国际标准化组织(ISO)颁布的信息安全管理体系(ISMS)规范标准。)拿出来看看了。二是业务安全,比如用户数据的隐私保护,之前安全只是作为保障而不是一种前台可见的竞争力,但现在安全需要封装起来对用户可见,对产品竞争力负责。直接影响公司营收的问题需要先解决。之所以把业务安全放在第二阶段而不是去优化安全基础架构是因为投入产出的边际成本,投在业务安全上,这一部分产出会比较直观,对高层来说安全从第一阶段到第二阶段一直是有明显可见的产出。
3.优化期
第三个阶段会感到开源工具不足以支撑业务规模,进入自研工具时代。
4.对外开放
第四个阶段,安全能力对外开放,成为乙方,不是所有的甲方安全团队都会经历这个阶段,故而此处不展开。
如何推动安全策略
1.公司层面
首先,推动安全策略必须是在组织中自上而下的,先跟高层达成一致,形成共同语言,对安全建设要付出的成本和收益形成基本认知,这个成本不只是安全团队的人力成本和所用的IDC资源,还包括安全建设的管理成本,流程可能会变长,发布链条会比过去更长,有些产品可能会停顿整改安全,安全特性的开发可能会占用正常的功能迭代周期,要认同做安全这件事的价值,你也要尽可能的提供轻便的方法不影响业务的速度。
2.战术层面
甲方安全团队思路受限的地方在于:总是把安全放在研发和运维的对立面上,认为天生就是有冲突的。我的建议是从现在开始不要再用“你们”这个词,而改用“我们”,自此之后便会驱动你换位思考,感同身受,真正成为助力业务的伙伴。其实有些问题处理的好,真正让人感到你提的建议很专业,研发和运维人员不仅会接受,而且会认为自己掌握了更好的编码技能或者安全配置技能而产生正向的驱动力。利用高层的大棒去驱动可能是一种屡试不爽的技巧,但我认为不是上策。安全策略的推动还依赖于安全建设的有效性。
安全需要向业务妥协吗
1.安全的本质
安全的本质其实是风险管理,绝对的安全可能吗,说绝对安全本身就是个笑话。攻防不对等,防御者要防御所有的面,而攻击者只要攻破其中一个面的一个点就可以了。接近于绝对安全的系统是什么样的?尽可能的不提供服务,提供服务也只提供最单调的数据交互模型,尽可能少的表现元素,那样的话还是互联网吗,还有用户体验可言吗?而且安全和成本永远要追求一个平衡。
2.妥协的原则
既然安全建设的本质是以一定的成本追求最大的安全防护效果,那一定是会有所妥协的。我认为安全本质还是为业务服务,如果业务死了,即使安全做得再好也没价值,更准确一点说,安全需要为业务量身定制,如果业务要轻装上阵,你给他重甲也不行,只能穿防弹背心。安全做得过于重度都是不合适的。坚持原则又懂得给业务让路,只是要把握好分寸,避免自己的好心被人利用,成为安全问题不整改的免责窗口,那样就事与愿违了。高危漏洞,有明显的利用场景,不能妥协。
对于不痛不痒的漏洞,以及待开发的安全功能,如果开发周期很长,受众群体很少,使用该功能的用户比例极少,边缘性产品,只影响某个中间版本到下个版本被其他机制完全取代了,诸如此类的情况可以考虑酌情妥协。妥协并非退让,而是大局观,最后补充一点:妥协不应该发生在工程师层面,而是应该在Leader和安全负责人这个层面。如果在安全工程师自己提的整改方案这个层面上,自己主动开始妥协了,那后面很多事情就没法做了。
选择在不同的维度做防御
1.技术实现维度场景
在纵深防御的概念中(参考后面的“技术篇”)企业安全架构是层层设防,层层过滤的,常见漏洞如果要利用成功需要突破几层限制,所以退一步对防御者而言有选择在某一层或某几层去设防和封堵的便利。
2.“一题多解”的场景
假如同一个问题有>1种解决方案,可能会因场景不同而面临选择。
3.跨时间轴的场景
回顾整个时间轴的防护措施依次是:临时性规避措施——push补丁/根治措施——取消临时性措施——添加常态性的特征检测措施——检测到漏网之鱼——继续上述过程。
4.风险和影响的平衡
风险缓解的原则是在以下三者之间做最大平衡:1)风险暴露程度;2)研发运维变更成本;3)用户体验的负面影响。
5.修复成本的折中
通常情况下改产品的成本是最高的,成本最高的往往不容易推动,推不动就无法落地,最后就是一堆安全问题。风险和修复成本去比较,在坚守底线的基础上选择最优解。
需要自己发明安全机制吗
1.安全机制的含义
安全机制包括:常见的对称和非对称加密算法,操作系统自带的RBAC基于角色的访问控制,自带的防火墙Netfilter, Android的基于appid隔离的机制,kernel支持的DEP(数据段执行保护),以及各种ASLR(地址空间随机映射),各种安全函数、服务器软件的安全选项,这些都属于已经存在的安全机制,注意我用的词是“已经存在”,而这个话题是针对是不是要在已有的安全机制上再去发明新的安全机制。
2.企业安全建设中的需求
实际上,在日常中发生的绝大多数问题都属于对现有安全机制的理解有误、没有启用或没有正确使用安全机制而导致的漏洞,而不是缺少安全机制,所以绝大多数场景都不需要去发明安全机制。
3.取舍点
首先要判断这是单个问题还是属于一类问题,如果是前者,用救火的方式堵上这个洞就好,没必要再去考虑更多。但假如这是一类问题,而你又没提出通杀这一类问题的手段就会永远处于救火之中,疲于奔命。当你过于勤奋地在很微观的细节上补洞却总是补不完的时候,不妨停下来看看能否在更高更抽象的层次上打个补丁。
如何看待SDL
安全开发生命周期(Security Development Lifecycle,简称SDL)是由微软公司提出的,从安全角度指导软件开发过程的管理模式。目的是减少其软件中的漏洞数量和降低其严重级别。SDL侧重于长期维护、流程改进并能够帮助开发过程应对不断变化的威胁状况。
图-SDL整体框架
1) 攻防驱动修改
通过对已知的攻击手段,例如SQL注入,XSS等建立事前的安全编码标准,并在发布前做代码审计、渗透测试和提出漏洞修补方案。这种模式的显著优点是针对性比较强,直入主题,见效快。
简单的流程+事件驱动型构成了这种日常行为的本质,简单的流程通常包括:
❑ 事前基线:Web安全编码标准,各公司内部范围流传的APP应用安全设计文档
❑ 事中措施:代码审计,发布前过一轮扫描器+渗透测试。
❑ 事后机制:HTTP全流量IDS, Web日志大数据分析,等等。
❑ 事件驱动:发现了新的安全问题就“事后诸葛亮一把”,做点补救性措施。
从整个过程看,攻防驱动修改比较偏“事后”,相对于完整的SDL,威胁建模等工作而言,它似乎不用发散精力投入太多就能覆盖已知的攻击点,而且在研发侧不用面对比较大的“推动SDL落地的压力。”但是它的缺点也是显而易见的,考虑不够系统性。
2) SDL落地率低的原因
1.DevOps的交付模式
互联网频繁的迭代和发布,不同于传统的软件开发过程。不过当你有经验丰富的安全人员和自动化工具支持时,SDL在时间上是可以大大缩短的。
2.历史问题
“事前用不上力,偏事后风格的安全建设”贯穿于大多数安全团队的主线。
3.业务模式
对于以Web产品为主的安全建设,第一是事后修补的成本比较低,屡试不爽;第二是部分产品的生命周期不长,这两点一定程度上会让很多后加入安全行业的新同学认为“救火”=“安全建设”。
4.SDL的门槛
第一点是安全专家少,很多安全工作者懂攻防但未必懂开发,懂漏洞但未必懂设计,所以现实往往是很多安全团队能指导研发部门修复漏洞,但可能没意识到其实缺少指导安全设计的积累,因为安全设计是一件比漏洞修复门槛更高的事。
第二点是工具支持少,静态代码扫描、动态Fuzz(Fuzz,也被称为模糊测试,是一种自动化的软件测试方法,主要用于发现软件中的实现错误。它通过使用格式错误/半格式错误的数据以自动化的方式来进行测试。在Fuzz测试中,应用程序/软件的反应会被观察,并根据其行为的变化(崩溃或挂起)来发现实现错误。)等。
3) 因地制宜的SDL实践
1.重度的场景
对于公司内研发的偏底层的大型软件,迭代周期较长,对架构设计要求比较全面,后期改动成本大,如果安全团队人手够的话,这种场景应该尽量在事前切入,在立项设计阶段就应该进行安全设计和威胁建模等工作。
2.轻度的场景
对于架构简单、开发周期短、交付时间要求比较紧的情况,显然完整的SDL就太重度了,这个时候,攻防驱动修改就足以解决问题。
其他的诸如小版本发布,技术上没有大的修改,也没必要去跑全量SDL,否则就太教条和僵化了。
4) SDL在互联网企业的发展
目前SDL在大部分不太差钱的互联网企业属于形式上都有,但落地的部分会比较粗糙。通常只有一两个环节。最主要的瓶颈还是人和工具的缺失。
STRIDE威胁建模
STRIDE是微软开发的用于威胁建模的工具,或者是说一套方法论吧,它把外部威胁分成6个维度来考察系统设计时存在的风险点,这6个维度首字母的缩写就是STRIDE,分别为: Spoofing(假冒)、Tampering(篡改)、Repudiation(否认)、Information Disclosure(信息泄漏)、Denial of Service(拒绝服务)和Elevation of Privilege(权限提升),如下表所示。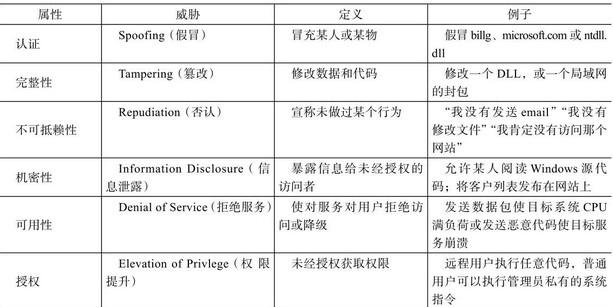
STRIDE是一个不错的参考视角,即便有丰富攻防经验的人也不能保证自己在面对复杂系统的安全设计时考虑是全面的,而STRIDE则有助于风险识别的覆盖面。
关于ISO27001
1.重建对安全标准的认知
安全标准归根结底是为了给你一个参考和指引,它本质上是用于开拓视野,跟堵不堵漏洞完全没冲突,换句话说它是一本书的目录,但对于每个章节怎么写则取决于你自己,你可以买WAF也可以加固容器,也可以像偏执狂一样地做代码审计,至于堵漏洞那只是每个章节里的一段文字而已。
2.最实用的参考
❑ ITIL(BS15000/ISO20000)——绝大多数互联网公司的运维流程都是以ITIL为骨架建立的
❑ SDL——研发侧的安全管理
❑ ISO27001——企业安全管理领域的基础性安全标准
3.广泛的兼容性
4.局限性
方法论的作用是解决企业整体安全从30分走向50分的问题,这个阶段需要具备普适性的有助于改善基本面全方位提升的东西。但是到了中后期,这些就不太管用了,只有依靠专业人士的技能和资源的集中投入才能有所产出。
流程与“反流程”
1.人的问题
首先有流程肯定能解决问题,但流程化是不是最佳实践则不确定。随着组织越来越大,流程会越来越多,并且流程大都不是“进取和开放”型的,而是“错误规避”型的。
流程的制作者为了保护既有权益,大多会僵化执行流程,开始走向自己的反面。作为安全负责人,必须周期性地审视安全和IT治理的流程是不是太冗余了,是否可以精简一下,或者在公司业务扩张、新建业务线的时候考虑一下原有的流程是否适用于新的领域。
2.机器的问题
流程是用来解决人容易犯错的问题,而不是用来解决机器犯错的问题,如何让系统和程序返回人所期望的结果是技术需要解决的问题,跟流程没关系,当然有人说跟程序的执行流程(routine)有关系,是的此流程非彼流程。
业务持续性管理
业务持续性管理(BCM)是一个较高层次的管理机制,通常对应到公司层面,它使企业认识到潜在的危机和相关影响,制订响应、业务和连续性的恢复计划,其总体目标在于提高企业的风险防范能力,有效地响应非计划的业务破坏并降低不良影响。
BCM的全生命周期方法论下图所示,其中BIA(Business Impact Analysis,业务影响分析)、Recovery Strategy(恢复策略),实施以及测试和演练都是很重要的环节。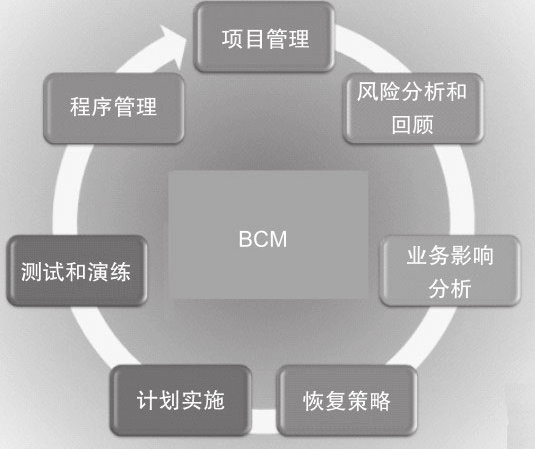
关于应急响应
应急响应有一个PDCERF模型(也可以参考NIST SP800-61)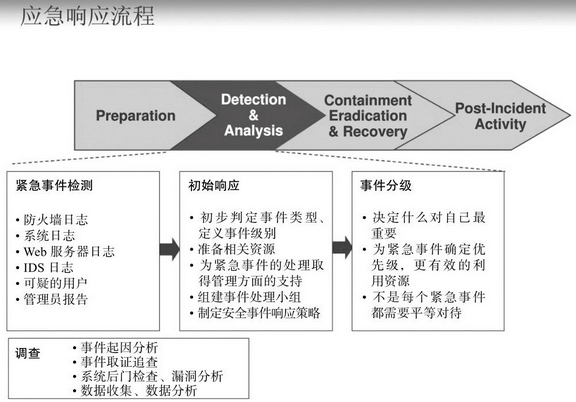
P是指Preparation(准备),D是指Detection(诊断),C是指Containment(抑制),这是被大多数人忽略的一步,首先应该是抑制受害范围,隔离使受害面不继续扩大,再追求根治。这跟ITIL的思路是一样的,问题发生时首先是用事件管理以平息事件,恢复SLA为目标,至于到底是什么原因可以先放一放,等恢复服务了,再用问题管理来解决根因的事情。,E是指Eradication(根除),寻找根因,封堵攻击源。R是指Recovery(恢复),把业务恢复至正常水平。最后,F是指follow-up(跟踪),监控有无异常,报告,管理环节的自省和改进措施,现在俗称安全运营的持续改进环节。之前说到抑制的环节,首先要了解业务、数据流、各服务接口调用关系,这些都是日常的积累,否则随便一个隔离又把什么服务搞挂了。反过来倒推,如果安全团队平时连个数据流图都没有的,发现单点出现问题症状时大致的系统间影响和潜在的最大受害范围都估计不出来的,那安全建设即便是救火也肯定是一团糟啦。
安全建设的“马斯洛需求”层次
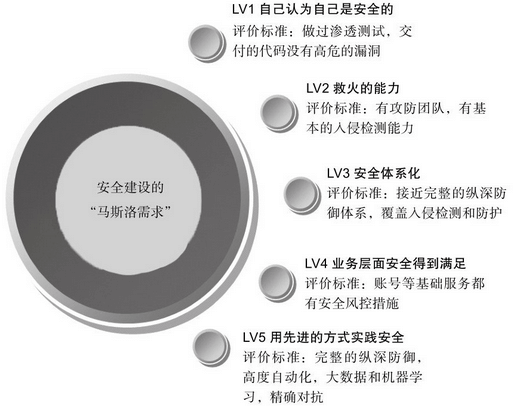
TCO和ROI
企业安全建设本质上不是一个可以通过完全量化的指标来衡量建设得好与坏以及能力成熟度的事情。
也是为什么等级保护、ISO27001、PCI-DSS这类企业认证可以用来装点“门面”,在广告、营销、融资、上市公司内控等环节告诉公众自己是有那么一点安全能力的,但是永远都不可能说我是无懈可击。可用于评价安全建设做的好与坏的唯一标准就是ROI,用什么样资源(TCO)产出什么样的安全效果。
在互联网公司,安全负责人最可能影响ROI的几个因素如下:
❑ 缺少系统化蓝图,对安全建设的全局以及分解后的轻重没有感性认知,这是最可能导致头痛医头脚痛医脚的原因。
❑ 对管理体系和工具链建设没有整体认知,选择在错误的时间点做正确的事。
❑ 把安全工作当成checklist而不是风险管理工作,凡事要求绝对安全而不能接受相对风险,对下属求全责备,大概只有外星人能满足这种需求。
❑ 弱于判断安全建设在实践环节的好与坏,搞不清楚某个安全机制在业界属于落后水平,平均水平,还是领先水平,以及某种安全机制对于削减某类风险的作用强弱,容易被执行者忽悠。带来的结果就是貌似很苦很努力,但收效甚微。
❑ 个人的职场步调与公司发展的阶段不一致,公司处于快速扩张时期,而安全负责人本人则采取保守谨慎的策略。
❑ 只务内勤,不管外联,不重视生态关系建设。最后导致小问题,大影响。
第4章 业界的模糊地带
- 关于大数据安全
1.大数据安全的分类
第一类:
企业在部署Hadoop/Storm集群时从采集存储到计算这套技术架构本身所涉及的安全问题。
第二类,以海量样本+机器学习的方法去处理安全检测问题
第三类,由于要处理的数据量比较大,传统的单机设备处理不了,所以需要用Hadoop之类的技术解决数据处理中的数据规模和实时性要求这两个性能问题,只是一个纯粹的性能问题,在有大数据支持团队的情况下,有价值的部分主要还在于建模的规则部分,即对安全问题的检测规则。
2.传统场景和大型互联网场景
在传统安全场景下通过采集各个终端安全软件的告警、日志,各个网络设备、安全设备的日志告警到一个数据源,用大数据进行多维度关联,最后展现告警,总体上用了一次大数据计算。而在大型互联网下终端可能不直接告警,而是以采集数据为主,在每一个维度的安全解决方案上都会有自己的大数据环境
新兴的解决方案和原来的安全措施本质上是演进、升级和补充的关系,不是替代的关系。
很多人觉得防火墙这玩意儿没什么价值量,但不代表它没有价值,防火墙的最根本作用是减小攻击面,而不是为了解决反弹木马这样的问题。
在解决实际的问题上,低成本、简单甚至无脑的手段只要能解决问题就好,高大上的东西并不见得一定“管用”、“好用”。第5章 防御架构原则
防守体系建设三部曲
1.信息对抗
信息对抗的目的是知己知彼,从两方面进行:数据化和社会化。数据化指的是企业自身安全风险数据建设与分析,需要根据基线数据、拓扑数据、业务数据梳理清楚可能存在的攻击路径与攻击面,针对性设防。需要持续运营,对于业务环境变更带来的新的攻击面与路径需要及时补防,往往纰漏也出现在对业务变更跟进不够及时的情况下。
2.技术对抗
针对攻击者,每个突破点可以在更高维度以及多维度进行检测与防守,这才能扭转攻防的颓势。把方案落地优化才能有最终的效果。这包括代码能力、海量数据运营、规则的优化。
3.运营能力对抗
运营能力主要体现在两方面:
1)风险闭环。简单说就是“一个问题不能犯两次”,通过闭环运营让企业自身安全能力不可逆地走向更好。
2)执行力。大规模生产网络的纵深防御架构
互联网安全有几个比较核心的需求:快速检测、有限影响、快速溯源、快速恢复。 - 防御者模型

第一层是安全域划分,这个安全域是对业务的抽象,并不是对物理服务器的划分,这个方案主要解决被无意识的扫描行为以很低的成本获取新的站点和权限,以及获得单点root后进一步渗透的扩散,希望能把安全事件爆发的最大范围抑制在一个安全域中,而不是直接扩散到全网。
第二层是基于数据链路层的隔离,只有第二层隔离了才能算真正隔离,否则只在第3层以上做ACL(ACL,全称Access Control List,是一种访问控制技术,主要用于控制网络设备(如路由器和交换机)上进出数据流的规则集。通过设置ACL,可以控制哪些流量可以进入或离开网络,从而提升网络的安全性。)效果会差一些,仍然会遭受ARP攻击(ARP攻击是一种网络攻击方式,主要通过伪造IP地址和MAC地址实现ARP欺骗,能够在网络中产生大量的ARP通信量使网络阻塞,攻击者只要持续不断地发出伪造的ARP响应包就能更改目标主机ARP缓存中的IP-MAC条目,造成网络中断或中间人攻击。)。
第二层之上就是端口状态协议过滤,这是绝大多数“防火墙”应用的场景。再往上一层是现在讨论最多的App安全,应用层通常是暴露在Internet上的攻击面,这一层主要是解决认证鉴权、注入跨站上传之类的应用层漏洞,尽可能把入侵者堵在信息和资源的唯一入口。应用层上方是容器、运行时环境。在绝大多数入侵活动中,上传或生成webshell是从应用权限向系统权限转化的关键一步,所以这一层的防御也是比较重要的。 - 互联网安全架构设计原则
1.纵深防御
整个企业的安全架构是由多层次的安全域和对应的安全机制构成的,要保护关键数据,需要层层设防,层层包围,这样就不太可能被攻击者得手一点就全部失守。
2.多维防御
对同一种攻击有多种维度的防御和检测手段,逃过一层还有额外机制,例如,对抗SQL注入,第一层WAF,第二层Web日志分析,第三层RASP,第四层SQL审计。
3.降维防御
降维防御是针对降维攻击而言的,大意是在攻击者不可达、不可控、无感知的更底层进行检测和拦截。
4.实时入侵检测
实时入侵检测偏重的是事中进行时的检测能力而不是事后的指标。
5.伸缩性、可水平扩展
6.支持分布式IDC
对于海量IDC规模,需要支持去中心化,多级部署,解决一系列的失效、冗余和可用性问题。
7.支持自动化运维
服务器数量一多,不能自动化运维就不具有实际可操作性、可维护性。
8.低性能损耗
9.能旁路则不串联
“分光”、“旁路”是互联网偏爱的一种方式,究其原因是不想对业务逻辑改动,串联型安全措施最有可能产生的问题是:
1)业务响应的延迟
2)误杀,阻断了正常用户的请求。
3)对业务逻辑的影响
10.业务无感知
业务无感知就是安全方案的落地尽可能地对业务侧:不断网、不改变拓扑、不改变业务逻辑、无性能损耗。无缝集成有时也是这个意思。
11.去“信息孤岛”
传统解决方案中单个安全设备注重解决“自己的事”。而互联网环境下单点的安全检测和防御是不行的,信息不能封闭在一个程序或设备中,必须可联动,可关联。
12.TCO可控
有些商业安全产品也许效果还凑合,小规模IDC部署可能没太多问题,而一旦进入海量IDC环境,即使给大客户折扣价也是个天文数字,而商业产品很多功能其实都是多余的,实际环境简陋的东西往往很有效,这就是自研的必然性。第6章 基础安全措施
安全域划分
安全域划分的目的是将一组安全等级相同的计算机划入同一个安全域,对安全域内的计算机设置相同的网络边界,
使得安全域内这组计算机暴露的风险最小化,在发生攻击或蠕虫病毒等侵害时能将威胁最大化地隔离,减小域外事件对域内系统的影响。
1 传统的安全域划分
通常会分出DMZ区和内网,在传统的安全域划分中还会通过硬件防火墙的不同端口来实现隔离。但是如今这种方法越来越多地只适用于办公网络,对于大规模生产网络,这种方法可能不再适用。
2 典型的Web服务
典型的Web服务通常是接入层、应用层、数据层这样的结构,其安全域和访问控制遵循通用的模型。
亚马逊Web服务的安全组(ACL)示例示例.png)
3 大型系统安全域划分
把不同的业务(垂直纵向)以及分层的服务(水平横向)一个个切开,只在南北向的API调用上保留最小权限的访问控制,在东西向如无系统调用关系则彼此隔离。
如果希望尽可能在内网少隔离,有利于弹性网络伸缩,前提是基于服务器的单点入侵检测和防护能力比较强。
4 生产网络和办公网络
保证最大的隔离,需要尽可能地采取如下几个方面的措施:
❑ 生产网络的SSH 22端口在前端防火墙或交换机上默认阻止访问。
❑ 远程访问(运维连接)通过VPN或专线连接到机房生产网络。
❑ 通过生产网络的内网而非外网登录各服务器或自动化运维平台。
❑ 办公网络中运维环境、发布源和其他OA环境VLAN隔离。
❑ 虽然在同一个物理办公地点,但运维专线和办公网络的接入链路各自独立。
❑ 为保证可用性,运维专线最好有两条以上且来自不同的ISP,防止单链路故障时无法运维。
❑ 跳板机有所有的运维操作审计。
有了这些隔离措施之后,“绕一圈”的渗透方法并非绝对不可行,但会难很多。系统安全加固
系统安全是所有安全工作的第一步,这部分内容可以归入安全基线。
1) Linux加固
1.禁用LKM
2.限制/dev/mem
3.内核参数调整
4.禁用NAT
攻击者在渗透内网时经常用到的一个技巧就是在边界开启端口转发,这样能提供一个方便的途径访问内网服务器,所以防御者要做的就是禁用IP转发
5.Bash日志
6.高级技巧
高阶的方法就是修改shell本身,不依赖于内置的HISTFILE,而是对所有执行过的命令无差别的记录。另一种shell审计的高级方式是将shell的log统一收集后基于机器学习,以算法学习正常管理员的shell命令习惯,而不是以静态规则定义黑白名单。
2) 应用配置加固
1.目录权限
“可写目录不解析,解析目录不可写”,这句话主要用于对抗webshell。
2.Web进程以非root运行
Web进程以非root权限运行遵循了最小权限原则。
3.过滤特定文件类型
通过rewrite规则把攻击特征的URL重定向到我们自己的页面,而避免让攻击者下载到不该下载的文件。
3) 远程访问
SSH是目前最常见的远程访问之一,使用SSH V2,而不是V1,禁止root远程登录。
4) 账号密码
对付暴力破解最有效的方式是多因素认证或非密码认证。作为甲方安全团队,平时也应该收集各种社工库,把公司内部研发测试运维常用的“弱”密码做成字典,周期性地更新这个字典并主动尝试破解公司内各个系统的账号,能破解的都视为弱密码,即可要求相关人员整改。防御者必须跟随攻击者的脚步,避免被“领先一个时代”。
5) 网络访问控制
在大型互联网里,购买商业防火墙产品可能会越来越少,大部分都会转为使用Netfilter+高性能PC服务器。很多时候需要在总出口部署几条类似于“黑名单”的总体策略。这个策略有可能是临时的,也可能是持久的,但在核心交换机上做太多NACL不合适,于是把NACL还是单拆出来,串联一个硬件防火墙,在防火墙上做具体的NACL。如果防火墙后的业务是确定开放某几个端口,则防火墙可以过滤所有的不必要端口充当起访问控制网关的作用。除了网关级的访问控制以外,还有机柜级的NACL和系统级的NACL。采用多层NACL的原因在于,一方面安全域之间需要隔离,安全域内部也需要划分,另一方面当某一层的NACL失效时,还有其他层的NACL在抵挡,不会马上变成“裸奔”模式。
6) 补丁管理
❑ 自动化运维:如何大批量地push补丁。
❑ ITSM成熟度:打补丁尽可能不影响在线服务的可用性。
❑ 架构容灾能力
❑ 系统能力:提供热补丁,不需要重启。
❑ 快速单个漏洞扫描:补丁push升级成功的检测。
安全团队需要考虑的是评估漏洞的危害和对自有系统的影响,这点依赖于很多能力,包括:1)资产管理和配置管理;2)海量IDC下的系统层和应用层漏洞判定。
7) 日志审计
日志成千上万,一开始就想建SOC的往往都是没有经验的人。
基础的数据源和告警的误报都没解决的时候,纵深防御体系还完全没弄起来,也就是生态链的底层地基都未建好,就直接想去建金字塔顶,那是理论派才做的事情。服务器4A
4A指:账户(Account)、认证(Authentication)、授权(Authorization)、审计(Audit)。
目前主要有两种方式:
1.基于LDAP
2.基于堡垒机第7章 网络安全
网络入侵检测
1.传统NIDS
笔者认为APT的解决方案目前更多的还是在办公网络,对生产网络而言NIDS(网络入侵检测系统)不会消亡,HIDS(主机入侵检测系统)会大放光彩。顶多只能说NIDS的产品形态正在发生改变,但APT检测无法取代NIDS。
2.开源SNORT
3.大型全流量NIDS
传统NIDS在大型互联网场景下有如下几个明显的缺陷:
❑ IDC规模稍大很容易超过商业NIDS处理带宽的上限,虽然可以多级部署,但无法像互联网架构一样做到无缝的水平扩展,不能跟基础架构一起扩展的安全解决方案最终都会掣肘。
❑ 硬件盒子单点的计算和存储能力有限,很容易在CPU时间和存储空间上达到硬件盒子的上限,即使有管理中心可以腾挪存储空间也解决不了这个问题。
❑ 规则数量是性能杀手,最不能被并行处理的部分会成为整个架构的瓶颈。
❑ 升级和变更成本高,可能对业务产生影响。
❑ IDC规模较大时,部署多台最高规格商业NIDS的TCO很高
针对大规模的IDC网络,
❑ 分层结构,所有节点全线支持水平扩展。
❑ 检测与防护分离,性能及可用性大幅提升,按需决定防护,支持灰度。
❑ 报文解析与攻击识别完全解耦,入侵检测环节“后移”。
❑ 依赖大数据集群,规则数量不再成为系统瓶颈,并且不再局限于基于静态特征的规则集,而是能多维度建模。
❑ “加规则”完全不影响业务。
4.关于D还是P
因为可以延时处理,所以D(detection)方案的门槛比P(protection)方案要低。对互联网服务而言,可用性是除了数据丢失以外的第二大严重问题,如果要实现P就会面临延迟和误杀的风险,因此P方案实际比D方案难了一个阶梯。P方案最终是一个打折扣的版本,利用DDoS引流-清洗(过滤)-回注的防护原理,将需要防护的流量迁移到清洗集群,清洗集群上的过滤规则绝对不会是商业NIPS广告宣称的那种大而全的,而是有针对性的几条高危漏洞规则,做一层很轻的过滤。在“和平时期”,一般不需要启用P功能,只使用D就可以。T级DDoS防御
- DDoS分类
1.网络层攻击
❑ Syn-flood
防御syn-flood的常见方法有:syn proxy、syn cookies、首包(第一次请求的syn包)丢弃等。
❑ ACK-flood
❑ UDP-flood
❑ ICMP-flood
2.应用层攻击
❑ CC——ChallengeCollapsar
❑ DNS flood——伪造源地址的海量DNS请求,用于淹没目标的DNS服务器。
❑ 慢速连接攻击——针对HTTP协议
❑ DOS攻击
3.攻击方式
❑ 混合型攻击
❑ 反射型攻击
反射型攻击的本质是利用“质询-应答”式协议,反射型攻击利用的协议目前包括NTP、Chargen、SSDP、DNS、RPC Portmap等等。
❑ 流量放大型攻击
❑ 脉冲型攻击
❑ 链路泛洪型攻击
链路泛洪(link-flooding),这种方式不直接攻击目标,而是以堵塞目标网络的上一级链路为目的。 - 多层防御结构
DDoS攻击本质上是一种只能缓解而不能完全防御的攻击。对于超大流量攻击而言,就是需要4层防御机制,再没有其他手段了。
1.ISP/WAN层
这一层通常对最终用户不可见,如果只是中小企业,那这一层可能真的不会接触到。当流量超过自己能处理的极限时,必须要借助电信运营商的能力。
中国电信专门做抗DDoS的云堤提供了“流量压制”和“近源清洗”的服务,流量压制是一种分方向的黑洞路由,黑洞路由是一种简单粗暴的方法,除了攻击流量,部分真实用户的访问也会被一起黑洞掉,对用户体验是一种打折扣的行为。在某些攻击流量特别大而用户流量极小的方向上进行黑洞路由,可以在保证大部分业务前提下解决边缘带宽拥塞问题,这对具备一定带宽储备和清洗能力但仍需保证出口带宽的云清洗厂商特别有意义,对中小型网站用户体验影响较大。相比之下,近源清洗可以在靠近攻击源位置对攻击进行清洗,在几乎不增加时延的前提下完成流量清洗。跟黑洞路由比防御方的成本比较高,且触发到响应的延时较大。在运营商防御这一层的主要的参与者是大型互联网公司、公有云厂商、云清洗厂商,其最大的意义在于应对超过自身带宽储备和自身DDoS防御能力之外的超大攻击流量时作为补充性的缓解措施。
2.CDN/Internet层
CDN并不是一种抗DDoS的产品,但对于Web类服务而言,却正好有一定的抗DDoS能力。更改CNAME指向,等待DNS递归生效。
3.DC层
Datacenter这一层的DDoS防御属于近目的清洗,就是在DC出口的地方部署ADS设备。
4.OS/APP层
这是DDoS的最后一道防线。这一层的意义主要在于漏过ADS设备的流量做最后一次过滤和缓解,对ADS防护不了的应用层协议做补充防护。
5.链路带宽 - 不同类型的企业
1.大型平台公司
对于IDC规模比较大又有钱的公司来说,防DDoS的口诀就是“背靠运营商,大力建机房”,在拥有全部的DDoS防御机制的前提下,不断提高IDC基础设施的壁垒给攻击者制造更高的门槛。
2.中小企业
追求ROI是主要的抗DDoS策略。第一种情况极度省钱模式,平时裸奔,直到受攻击才找抗DDoS厂商临时引流,绝大多数企业都是这种心理,得过且过,能省则省,这也无可厚非,不过遇到关键事件要知道上哪儿去找谁,知道做哪些事。第二种情况追求效果,希望有性价比高的方案。 - 不同类型的业务
1.Web
对于Web类服务,大型平台的一般都是4层全部拥有,规模小一点的企业一般购买云清洗, cloudflare类的服务即可。
2.游戏类
通过DNS引流和ADS来清洗。ADS不能完美防御的部分可以通过修改客户端、服务端的通信协议做一些辅助性的小动作,防御机制基本都依赖于信息不对称的小技巧。 - 服务策略
❑ 分级策略
针对不同的资产使用不同等级的保护策略,能造成平台级SPOF(单点故障)的服务或功能应投入更高成本的防御措施,所谓更高成本不仅指购买更多的ADS设备,同时可以建立多灾备节点,并且在监控和响应优先级上应该更高。
❑ Failover机制
基础设施和应用层面建立冗余是技术形式上的基础,光有这些还远远不够,需要有与之配套的DRP&BCP策略集(DRP&BCP策略集是在面临灾难或业务中断时,确保业务连续性和数据恢复的重要策略。同时,还需要制定应急预案,如灾难恢复计划(Disaster Recovery Plan,DRP)和业务连续性计划(Business Continuity Plan,BCP),并进行真实的周期性的演练。),并且需要真实的周期性的演练,意在遇到超大流量攻击时能够从容应对。
❑ 有损服务
在应用服务设计的时候,应该尽量避免“单点瓶颈”,避免一个点被DDoS了整个产品就不好用了,而是希望做到某些服务即使关闭或下线了,仍然不影响其他在线的服务(或功能) - 破防和反制
完全的防护能力是建立在人、策略、技术手段都生效的情况才有的,如果这些环节出了问题,抗DDoS的整个过程可能会失败。链路劫持
1.HTTPDNS
HTTPDNS原来是一个为优化用户体验发明的东西,其本质就是利用HTTP协议来完成域名解析,防止被运营商劫持,当然并不是绝对的,HTTPDNS的请求由于是明文的,理论上完全可以劫持。只不过劫持的代价比原来更大一些。如果希望完全规避DNS解析劫持的问题,需要使用加密的DNS请求。
2.全站HTTPS
全站HTTPS主要解决当前越来越严峻的网民隐私泄露问题,减少被中间人监听和会话劫持的可能。
3.登录过程加密
4.跨IDC传输加密应用防火墙WAF
应用防火墙(Web Application Firewall, WAF)是Web应用防护系统,也称“网站应用级入侵防御系统”。
通过针对基于HTTP/HTTPS协议的流量建立检测或拦截规则,实现安全防护的目的。 - WAF架构分类
1.cname部署
2.module部署
module部署的WAF典型产品是开源软件ModSecurity。
3.网络层部署
此类WAF产品是最易部署的方式,它可部署在机房或某被防护的网络入口位置。
4.混合型WAF架构 - WAF安全策略建设
通常一个WAF产品起码会有两类规则:1)通用型主流漏洞检测与防护;2)最近出现高危1day\0day漏洞检测与防护。
1.主流Web漏洞检测规则
安全工作有一个重要的特点:需要及时更新。
WAF规则建设流程
2.最新高危漏洞检测规则
安全系统运营最重要的工作内容之一,除了部署覆盖就是检测能力的迭代更新。WAF系统对最新漏洞攻击的阻断也称为“虚拟补丁”,意为非真正的安全补丁,只是临时封堵攻击行为,为业务方真正更新补丁赢得宝贵的响应时间。威胁情报的获取通常可以通过情报渠道、订阅安全工具开发社区RSS、关注相应APP官方安全信息等方式。
3.业务风险监测规则
这里的规则多数分两类:1)已发现的业务漏洞,需临时封堵攻击行为,为漏洞修补赢得时间;2)某些高危或异常行为的监控,主要目的生产数据,为业务异常行为分析提供数据基础。 - WAF性能优化
1.架构优化
选择考量的因素包括团队能掌控与选择的资源,业务方对性能的敏感度,最后才是安全运营与检测能力效果的考量
2.规则优化
❑ 算法优化——WAF的流量匹配不能粗暴地直接丢给正则引擎,那会带来大量的不必要的开销。
❑ 正则优化
WAF支持规则配置不同的正则引擎。第8章 入侵感知体系
主机入侵检测
主机入侵检测系统(Host-based Intrusion Detection System, HIDS)顾名思义是基于主机的入侵检测系统,是部署在需要防护的主机服务器上的一种软件。
1 开源产品OSSEC
OSSEC拥有基础的入侵检测能力,同时也可以看做是一个基础数据采集和分析框架引擎,如果需要新增检测能力,通过增加数据和分析规则是可以实现的。
2 MIG
Mozilla InvestiGator是一个开源的分布式取证框架,
整体上MIG偏向于事后的取证,而不是实时的入侵检测,所以只部署MIG还不能实现主机侧的入侵检测,必须辅之以其他的Agent,如OSSEC或Osquery等。
3 OSquery
Facebook的开源项目OSquery
是把操作系统当做一个数据库,各种系统信息可以用SQL语句的方式来查询,
能否实现实时入侵检测的关键在于你采集数据的维度和云端的检测方法。
4 自研Linux HIDS系统
4.1 架构设计
❑ 行业法规需求
❑ 基础安全需求
❑ 企业自身的特殊安全风险需求
❑ 运维体系\网络环境适应
4.2 Agent功能模块
Agent分三个部分,安全功能模块、数据传输、管理模块。
列举常见模块
1)基线安全——
采集主机上配置版本信息。
2)日志采集
3)进程信息——
进程命令信息无论是作为运维操作审计,还是入侵行为分析都有极大帮助。
4)网络连接信息
5)webshell
inotify文件监控,Linux系统里的webshell检测
6)DB审计
4.3 数据传输
1)避免数据传输波峰“雪崩效应”
2)敏感数据脱敏及加密,很多数据中包含敏感信息,如http请求里的cookie、命令行里的密码。
3)做好每个数据传输环节的前后链对账,当出现安全事件漏报时能及时追查到可能导致数据丢失的环节,便于后续的优化与debug。
4.4 控制管理
❑ 健康度监控
❑ “自杀”机制——
安全在极端情况,以及出现故障的时候必须为业务稳定牺牲。
❑ 部署与更新——
重点关注两个方面:
1)海量环境影响
需要设定以下原则:
· 发布前必须通知业务方,必须有应急预案和回滚手段。
· 遵循灰度发布原则,未经一个可靠的时间周期(通常一个月)稳定运营验证,不得批量部署。不同业务环境分别灰度。
· 节假日前不部署。
· agent更新行为由Server端推送任务完成。
2)安全性——
必须设定几个安全原则:
· 控制(更新)指令仅允许选择固化的指令,严禁在Agent端预留执行系统命令的接口;
· 更新包必须经过第三方安全工程师审核之后上传至更新Server保存,更新仅允许选择更新Server上已有的安装包;
· 控制指令下发时必须由第三方审核批准才可执行。检测webshell
1.静态检测
2.流量监测RASP
Java RASP(Runtime Application Self-Protection)是一种在Java应用程序运行时进行自我防护的技术。Java RASP的实现主要依赖于Java Instrumentation技术,以及Java字节码操作框架。数据库审计
1.旁路型
通过网络设备镜像流量,审计设备解码组包DB流量,并存储分析,通过模型检测和追溯可疑和高危事件。
2.主机型
主机型的DB审计产品可以是单个进程也可以是HIDS的某个模块
3.代理型
4.攻击检测
DB审计安全产品主要解决两个问题:1)SQL注入拖库;2)操作违规审计。入侵检测数据分析平台
- 架构选择
部署于主机和网络上的设备只被限制在实现提取数据功能。分析与计算在后端也就是所谓的云端来实现。 - 功能模块
1.感知能力(网络数据采集、主机信息采集、应用服务记录)
2.数据分析(数据格式化、入侵检测规则、全局数据挖掘) - 分析能力
在原有特征检测技术之外,用行为模型能更好地检测入侵,通过行为模型实现检测能力,避免了各自漏洞技术细节差异带来的规则库冗余(且影响安全系统性能),也避免因检测规则过分针对细节(特征库\漏洞库)可能导致的被绕过。入侵事件数据化、入侵检测模型化、事件分析平台化。数据链生态——僵尸网络
- 僵尸网络传播
botnet或蠕虫,一个重要的特征就是自动传播能力,2类常见的传播方式。
❑ 漏洞传播
❑ 自动化攻击工具 - 应对僵尸网络威胁
日常安全工作中通过对入侵检测数据的分析,能感知到僵尸网络的演变以及0day\1day\Nday的攻击趋势。当僵尸网络在其初期,尚未形成规模之时,如果及时联合业界安全联盟加以打击,必将其扼杀在摇篮。安全运营
1.安全方案选型
2.安全事件的闭环运营
俗话说“一个人不能在同一个坑里摔两次”,我们迫切需要通过对安全事件闭环运营,完善每次发现的短板。
3.可量化的安全能力第9章 漏洞扫描
漏洞是指缺少安全措施或采用的安全措施有缺陷,可能会被攻击者利用,对企业的信息资产的安全造成损害。 漏洞扫描就是利用扫描器发现漏洞的过程。 - 按漏洞类型分类
1.ACL扫描
ACL扫描是用来按一定的周期监视公司服务器及网络的ACL的,比如无需对外开放的端口或IP是否暴露在了公网中。
ACL扫描的周期至少为一天一次
对于服务器数量较少的公司,可以直接用nmap扫描
2.弱口令扫描
常见的扫描器如Nessus、x-scan、h-scan、Hydra都具备弱口令扫描的功能
注:弱口令是高危漏洞,扫描到后需要业务部门第一时间修复。
3.系统及应用服务漏洞扫描
常见的系统及应用服务漏洞扫描器有Nessus及开源的openVAS
4.Web漏洞扫描
业内常用的Web漏洞扫描工具列表如下:
❑ Acunetix Web Vulnerability Scanner(AWVS)
❑ IBM Rational AppScan
❑ sqlmap
❑ w3af
❑ arachni
❑ Zed Attack Proxy
以上几款扫描器中,前2款是商业软件,后几款是免费开源的。 - 按扫描器行为分类
1)主动扫描
2)半被动扫描器
3)全被动扫描器
常用的AWVS、Sqlmap、Nessus等都是主动扫描器。全被动扫描部署方式上类似于IDS,不主动爬URL,而是对B/S & C/S双向交互的数据流进行扫描以期发现漏洞,全被动扫描的特点如下:
1)不需要联网,不会主动爬取URL,不会主动发出任何数据包。
2)更关注漏洞感知,而不是入侵行为。 - 如何应对大规模的资产扫描
总体思路是减少工作量,有几个方法:
1)简化漏洞评估链,减少需要扫描的任务。
2)减少漏洞扫描的网络开销和被检查者的性能损耗。
3)减少漏洞扫描的种类。
4)减少手工确认的工作量。第10章 移动应用安全
- 签名管理
推荐的解决方案是建立签名服务器,开发者上传需要签名的应用,服务器完成签名后提供下载。
签名服务可对申请应用签名的人员进行权限控制,并包含日志记录,保存上传应用副本等功能,这样做的好处是降低私钥泄露的风险。 - 应用安全风险分析
一些具体的风险列表:
❑ 应用间通信(IPC)
❑ 远程数据 - 安全应对
对于三方的选择,建议选取保持更新的开源项目,查看项目升级日志中修补过的安全列表,确认应用中将要使用的版本是否已经修补已知安全问题,并订阅此项目的版本更新邮件,能在之后发布安全更新时第一时间评估影响。具体到自身代码的引入的问题,需要符合最小化原则。另外两方面就是在需要时提供完善的认证和加密机制。 - 安全评估
1.代码审计
2.应用加固 - 关于移动认证
为了方便用户登录认证,通常移动应用通过保存登录信息或者加上简单的本地认证方式(如手势密码或者数字PIN码)来使用户免于输入完整的流程。第11章 代码审计
- 自动化审计产品
Foritify, Coverity, FindBugs等
这些自动化的代码审计产品能够满足对审计量和强度的要求,并且大多提供和开发环境相整合的组件,可以融入到日常的开发和编译过程当中。工具不可避免会产生漏报和误报,在处理工具生成的报告时,需要人工对生成的结果进行验证。第12章 办公网络安全
服务器网络大多是来自客户-服务端相对固化的交互模型,用严格的ACL就能控制绝大多数行为,但是办公网络却不一样,大量的客户端行为,所以办公网络的解决方案完全不同于生产网络,基本可以当作两件事情来对待。 - 安全域划分
办公内的安全域一方面是为了隔离威胁,另一方面是为了把安全域作为实施安全策略的最小分组单元,以便于对不同的单元附加不同的策略。 - 终端管理
1.补丁管理
2.组策略(GPO)
组策略的作用主要在于实施一些“基本的”安全策略。
3.终端HIPS(AV)
4.网络准入NAC
目前主流的网络准入主要有两种方式:802.1x,基于终端管理软件的C/S模式认证。 - 安全网关
1.NGFW/FW:NGFW(下一代防火墙)和FW(传统防火墙)在功能和技术上有显著区别。NGFW是在传统防火墙的基础上发展起来的,它不仅继承了传统防火墙的包过滤、状态检测等基本功能,还增加了诸如应用程序感知、身份认证、入侵防御系统(IPS)集成、深度包检测(DPI)等高级功能。
2.UTM/反病毒网关/NIPS(网络入侵防护系统)/反垃圾邮件
UTM(Unified Threat Management,统一威胁管理)是一种集成了多种安全功能的网络安全设备,主要用于保护企业网络免受来自外部的威胁,如病毒、入侵等。
3.堡垒机
堡垒机虽然部署在办公网络的网关处,但主要为生产网络的远程接入提供行为审计。
4.行为审计
行为审计主要是对员工上网行为做审计 - 研发管理
1.防泄密
一般情况下会给研发配两台PC,一台能畅游互联网随心所欲,另一台则用于coding不能访问互联网,个别需要复制粘贴的资源通过服务器的共享文件夹来中转,或者使用其他方式实现双机剪切板共享。在物理安全上,最好的方法还是机箱上锁,组策略中禁用USB的数据传输功能,保留鼠标、画图板和充电的功能。
2.源代码管理
最新的源代码至少在公司的平台上有一份完整的拷贝,同时由IT部门做好复制和灾备的工作。具体在权限上应该如何划分,实际上是一个文化的问题,而不是一个技术问题。遇到有的人喜欢擅自把源代码同步到GitHub这种地方去的,最怕是把密钥也同步出去,安全部门就要考虑写个爬虫去GitHub抓一下关键字。 - 远程访问
远程访问(例如VPN等)最大的问题是暴力破解,对于较大企业而言,一般都会选择双因素认证。 - 虚拟化桌面
虚拟化桌面的实际计算资源都在IDC机房的服务器集群上,所以在安全管理上有两大便利:
❑ 通过严格的统一安全策略可以使终端用户“能做的事情”和攻击面大幅减小。
❑ 原来要在每台服务器上安装杀毒软件,现在不用那么麻烦了,所有的入侵检测针对“服务器”做就可以。
❑ 审计比原来更容易做
以前很多人有技术洁癖,公司的安全方案必须“一刀切”, “大一统”,其实只要公司大过一定的规模,真没必要。 - APT
APT,即高级持续性威胁,是一种针对特定对象,长期、有计划、有组织的网络攻击行为。抗APT本质上是有实力的安全公司和极少数实力与安全公司对等的甲方安全团队玩的东西。用蜜罐(蜜罐(Honeypot)是一种网络安全技术,主要用于诱骗和监测网络攻击)是在办公网络中一种不错的入侵检测手段,但是在大型生产网络里不适合作为主要手段,而应该是一种补充手段的方案。 - DLP数据防泄密
数据丢失预防(DLP)是一种用于确保组织数据得到适当维护和控制的工具。DLP(Data Loss Prevention)的主流方案目前在互联网行业落地可能都存在有不小的问题,在兼容用户体验、性能方面仍有很大的改进空间。 - 移动办公和边界模糊化
- 技术之外
办公网络中的安全问题,因为涉及“人”的因素非常多,单纯依靠技术能解决问题的占比更低。制订“信息安全管理制度”也是必须的,它应该在新员工入职培训期间就根植于雇员的意识中。第13章 安全管理体系
安全管理体系是一个随业务扩张而逐渐完善的过程,并不是一上来就套一个大而全的安全体系。1 组织
对于比较大型的公司及平台,安全团队规模也比较大,通常分为两队:一队做传统的攻防对抗领域,一队做偏于业务安全上的“风控”。2 KPI
IT平衡计分卡这样的工具提供了高纬度的参考。
在支撑业务提升效率,对应到安全工作,有几个方面:
❑ 覆盖率——安全能力在公司内的普及程度,推动能力很考量软技能,不能支撑公司所有业务的安全活动也是安全团队的责任,争取到必要的资源也是责任之一。
❑ 覆盖深度——虽然在资源有限的条件下,很难做到覆盖率和覆盖深度两项全满贯,但是对于部门内部长期的工作改进而言,覆盖深度是一个可以持续优化的方向。
❑ 检出率/主动止损率——已有安全机制对攻击入侵行为的有效检测率(漏报和误报)
❑ TCO/ROI——用了多少资源,支撑了多少业务,支撑的深入程度,达成的效果的综合反映。
❑ 技术维度指标——入侵感知检出率、入侵感知误报率、入侵感知反应时长、网络层抗DDOS能力、安全方案伸缩性、安全方案可用性、1day漏洞主动发现时长、高危漏洞全网排查时长、高危漏洞全网修复时长……3 外部评价指标
❑攻防能力
❑视野和方法论
如果只强调方法而不强调攻防就会陷入纸上谈兵,但反过来只强调攻防不强调方法就会陷入全员救火队的状态。
❑工程化能力
❑对业务的影响力——这一点跟内部的影响力,跨组织的沟通能力,推动能力,团队视野有很大的关系。安全做得最好的企业一定是将安全和风险意识根植于企业文化中。4 最小集合
1)建立事前的安全基线,各种安全编程规范、运维配置规范等。
2)事中的发布&变更环节的安全管理。
3)事后的救火机制。
4)把救火逐步转化为防御机制或对现有安全策略升级的流程(或团队意识)。
5)整个公司或至少业务线级别的周期性风险评估,主要用于识别新的风险和潜在的可能转为安全事件的诱因,以此审视目前的安全体系中是否缺少必要的自检环节。
4.1 资产管理
搞清组织中一共有多少需要纳入安全管理范畴的资产是所有安全工作的基础,督促相关部门进行有效的资产管理并使用自动化的手段发觉资产的变更,是运维和安全部门共同需要考虑的事情,尤其在资源云化的时代,资产管理是最基础的要求。在有了基础的资产管理以后,对资产做分类分级,既是信息安全的需求,也是BCM的基础要求,同时隐私保护也有这个需求。
4.2 发布和变更流程
4.3 事件处理流程
4.3.1 角色定义
1)联系人(运维或安全)
2)执行者(运维/研发/安全)
3)指挥人(技术体系主要负责人)
4.3.2 定义职责矩阵
4.3.3 流程图
在安全事件的处理方法上应遵循PDCERF模型以及NIST-800中所定义的应急处理方法。
4.3.4 系统关联影响
SOA服务治理、接口间调用关系和数据流梳理,嵌套引用关联影响反映了内部治理的水平。5 安全产品研发
规模效应决定性价比的问题。打算自研某个安全产品一定是应用场景覆盖的IT资产超过某个数量级,这样所花费的人工研发和维护的成本才会小于同等数量级的IT资产使用商业解决方案时采购的总花费。对于攻防类的安全产品比较容易获得通用的商业解决方案,但对于风控类的产品,由于跟业务强相关,几乎鲜有现成的解决方案,所以风控侧相较而言自研的需求和必要性更大一些。6 开放与合作
SRC(安全应急响应中心)只是一个形式上的开端,其更大意义上是指安全工作,应该走出去寻求与业界广泛的合作。第14章 隐私保护
个人、企业、国家这3个层次决定了隐私保护的重要性,对于互联网企业而言,隐私保护在业务角度有如下诉求:
❑ 防止盗号,撞库,用户(玩家)数据泄露,数据被供应商和分包商非法倒卖。
❑ 防止信息过度搜集,以及在用户不知情、无选择权的情况下被收集和存储。
❑ 有跨境业务时,需要遵从当地的合规性要求,否则不能准入。
❑ 跨境数据传输需要通过专门的法律框架。
❑ 有完整的安全体系和技术措施保护数据。
❑ 设置专职的隐私保护职位(高管)。
❑ 供应链上下游环节对隐私保护的遵从性。
❑ 提供审计的手段。
❑ 法律承诺,违约赔偿和违约责任。数据分类
隐私保护强调的是个人数据PII(Personally Identifiable Information),这与纯粹的服务器数据保护仍有差别。访问控制
访问控制(Identity & Access Management, IAM),典型的IAM应该包含如下几方面的元素:
1)谁(定义角色)
2)对哪些资源(定义对象)
3)拥有(定义“允许”还是“拒绝”)
4)哪些具体权限(定义增删改查和其他的操作)
5)有效期是多久(定义失效时间)
在此基础上还可以继续添加:组策略、通配符、根据条件触发或定义访问控制策略、多因素认证等。数据隔离
敏感数据(例如用户库、口令、密保、支付等)应考虑分表分库存储,应尽量减少一个上层应用出现漏洞时的影响,从安全上应考虑敏感数据的集中存储,过于分散会加大监控的成本,因为“如果所有的都重要那就等于没有一样是重要的”,对于终端设备,应考虑沙箱级隔离,屏蔽非法程序的恶意访问,或合法程序的非授权越界访问(B厂的App访问A厂App的个人数据)。容器本身使用TPM(可信计算)等技术。在云的虚拟化环境中,一般情况用VPC隔离。数据加密
选择性字段加密,目前可以使用的技术包括TDE(Transparent Data Encryption,透明数据加密)和应用级加密,对于非结构化数据,例如,文件、图片一般使用自实现的文件加密或磁盘块加密。在数据传输过程中TLS成了目前事实上的标准。
1.TDE透明数据加密
TDE可对数据和日志文件执行实时I/O加密和解密,这种加密使用数据库加密密钥(DEK),该密钥存储在数据库引导记录中以供恢复时使用。
2.应用加密
3.FPE(保留格式加密)
FPE(保留格式加密)则要求加密前的明文与加密后的密文拥有相同数据长度和数据类型,
FPE不仅可以解决敏感数据加密的问题,还可以解决将生产环境数据迁移到测试环境又不泄露用户数据的问题,除了持久化数据,FPE在数据传输过程中也一样可以使用。
4.文件/磁盘加密
高性能的磁盘加密一般都通过硬件加密芯片实现。
5.噪音混淆
噪音混淆就是在正常的用户数据里掺入“噪声因子”,它并非一种加密算法(这里并不是在讨论K匿名、差分之类的话题),而是变换了形式让数据不再以原来的面貌出现。密钥管理
密钥本身的存储和管理可能比具体怎么加密更重要,而一旦密钥丢失,所有的数据将不可找回。
密钥管理基础设施(KMI)通常分两部分:密钥的存储,对密钥本身的访问授权管理。更上层的加密方法通常由应用自身去实现。安全删除
对于加密数据或加密文件系统,不需要删除数据,只需要使用安全的方法删除加密密钥,对于非加密数据,需要使用安全的方法不仅格式化元数据,而且还要重写数据块,物理上可以使用消磁等手段。匿名化
为了尽可能地解绑个人隐私和用户行为的关系,出现了匿名化的产品设计理念,例如苹果用一个UUID(Universally Unique Identifier,通用唯一识别码)作为用户标识内容分级
对于隐私相关的重要数据只有通过完整的多因素认证或者基于风控系统的判断为可信访问时才开启。第15章 业务安全与风控
对抗原则
业务安全的策略和原则,具体如下:
相对的风控而非绝对的防黑——业务安全的目标是相对意义上的风险控制,而不是绝对意义上的防黑。
增加黑产的成本而非阻断他们的行为。
永远的情报——知己知彼,百战不殆。
方法比技术更重要——上兵伐谋,最下攻城。
数据比算法更重要。
勤能补拙。
忽略性能、用户体验和成本的风控没有意义。
纵深防御。
杀鸡给猴看——只要条件允许,用法律武器端掉主力,用风控手段扫尾。2:8原则,对危害最大的部分不一定要用常规手段,无论什么土方法,能达成目的就好。
人民的战争——教育正常的用户安全意识,动用一切资源和手段反剿黑产,以资鼓励全民情报。
社工库——敌人有的,我也要有。账号安全
1.注册
对抗垃圾注册一般的手段包括:
❑ 图片验证码
❑ 邮件验证码
❑ 短信验证码
❑ 语音验证码
❑ 电话语音验证码
对于利用注册接口检测用户名/账号是否存在的暴力枚举也应该做人机识别。以防止批量得到账号信息用于批量扫号等动作。
2.登录
使用风控系统对比用户画像检测登录地域来源、IP属性、可信设备、登录频率、代理使用习惯等从而推送不同复杂等级的验证码或开启多因素认证。
或根据离线数据,即一段时间内的请求(行为)异常,以及其他业务风控子系统判断的行为异常,再调用风控的接口推送二次认证要求做人机识别
3.密保/密码找回
首先平台应提供多种密码保护手段,并在用户界面显眼处提示或安全教育。其次,应确保平台的密码找回/密码重置等功能不存在逻辑漏洞可以被绕过,或发生过度信息披露。账户展现本身不应该存在可以被爬虫抓取聚合后用于撞库或暴力破解的信息。
4.多因素认证
重要的操作必须使用2FA(双因素认证)或MFA(多因素认证)
5.多设备登录
多设备登录时,应保证同平台不能“串号”。多设备同时登录时应支持交叉认证。
6.账号共享体系
对高安全域的应用,登录除了SSO token之外,引入第二层认证的secure token。电商类
1.恶意下单
拍下商品但不付款,旨在侵占库存,一般的对策是高峰时段下单使用验证码,下单后一段时间不付款订单自动失效,限制下单频率,有风控数据源可以对恶意账户进行标记,冻结下单。
2.黄牛抢单
对于恶意养号,抢购开始前就能在账号层面冻结掉。在活动开启前如果抢单程序是针对既有页面逻辑的,可以临时更换业务逻辑使抢单程序失效。在抢购过程会使用验证码做人机识别。
3.刷优惠券和奖励
首先要在账号层面根据大数据标记账户恶意灰度,其次优惠券跟账号绑定,无法流通和交易。
4.反价格爬虫
价格爬虫主要是竞争对手比价。
爬虫的特征
做人机识别
5.反欺诈
根据账户注册信息的真实性、登录设备的真实性、绑卡异常、账号异常,结合自有或第三方历史征信数据综合判断欺诈的可能性。
6.信息泄露
信息泄露有几大来源,撞库、用户信息过度展现和披露、开放平台API滥用、供应链上下游信息泄露,“内鬼”兜售内部数据。
7.交易风控
交易风控依赖于几个方面:
1)账户安全
2)客户端安全
3)认证机制
4)风险评估
交易风控在传统安全(包括认证、账户、KMS、PKI、客户端完整性等)基础上还需要由3大组成部分:
❑ 用户数据、交易数据。
❑ 来自传统金融行业的风险管理。
❑ 基于大数据的风控平台。广告类
因为点击欺诈非常严重,数据作假水分很高,所以目前都是按广告效果、实际订单效果收费。
按千次展示付费(Cost Per Mille,CPM)、按点击付费(Cost Per Click,CPC),基本都是CPA为主。CPA是指按照特定转化行为(如注册、下载、提交表单等)计费的广告形式,即“按转化付费”(Cost Per Action)。媒体类
媒体类的问题主要是黄赌毒、舆情安全。基础的手段包括:敏感字过滤、设置举报功能、加上人工审核。高级的手段本质上就是搜索引擎的技术:抓取样本,用机器学习的方法做特征识别。第16章 大规模纵深防御体系设计与实现
- 设计方案的考虑
因为安全手段要适应业务,必须有所妥协,而不能只以安全效果最大化来衡量。所以本着为业务让路的原则,最后就变成检测手段很多,阻断手段一般不轻易用。
1.数据流视角
从各个维度采集数据然后用大数据(包含机器学习的方式)最终生成攻击告警信息。
2.服务器视角
通过不同功能服务器上的数据采集点,构成入侵感知的数据来源。
3.IDC视角
业务规模稍微大一点就会自然牵扯到跨IDC,跨全球区域这些问题。一般情况下,为了兼顾多维度数据关联的准确性,会使用多级日志聚合到一个中心计算节点,在最终数据集上生成攻击检测告警。
4.逻辑攻防视角
从抽象的纯攻防视角如图所示
- 不同场景下的裁剪
1.IDC规模大小的区别
对裁剪影响最大的便是IDC规模,因为它决定安全的总投入。
2.不同的业务类型
如果业务流量中大部分都是HTTP类型的,那么应该重点投入WAF、RASP和Web扫描器,对于大量的非Web业务,例如很多存储节点,也只需要关注操作系统的入侵,更多的在HIDS上投入,重点在后门程序和Rootkit检测。
3.安全感的底线
尽可能地在数据库(或DAL,数据访问层)和主机这两个层面设防。第17章 分阶段的安全体系建设
宏观过程
第一阶段是基础安全策略的实施,是ROI最高的部分。这一部分大多属于整改项,不需要太多额外的投入就可以规避80%的安全问题
这一阶段总体上属于“饿不死”。
第二阶段是进入系统性建设,各个维度的安全防御手段。入侵检测等,除了技术上,还包括流程和审计需求。
第三阶段,系统化建设,安全运维和SDL成体系之后,可以选择性关注业务安全的问题。通常以账号安全为切入点,之后选择主营业务中风险最大的IT流程活动做相关的业务风险分析和业务风控体系建设。接下来的工作是进入运营环节,也就是所谓的PDCA的工作,把每一个防御点打磨到极致。
最后一个层次,安全建设进入“自由发挥区间”,这个区间做的事往往跟平台的经营状况,业务的市场地位,业务的全球化属性有很大的关系,已经无法给这个区间的事情贴标签,但也有一些可遵循的参考物,比如对标业界领导厂商。清理灰色地带
第一阶段:
1)资产管理的灰色地带
2)安全措施的覆盖率和健康状态
3)ACL的有效性
即使有了流程也不完全可依赖,因为基于人的流程是会犯错的,基于机器的流程才稍微可信点。
第二阶段:
1)清理远程登录弱口令。
2)清理Web应用
3)清理服务端口建立应急响应能力
1.组织
1)运维团队负责跟系统、数据库、中间件、网络基础架构相关的补丁和配置更改的具体实施工作,例如第三方开源服务器软件Nginx、OpenSSL、MySQL的漏洞。
2)产品团队负责产品相关的代码级别的漏洞修复(如果是自己开发的产品的漏洞)。
3)安全防御体系建设小组负责在相关的入侵感知体系中update对应该漏洞的检测规则。
2.流程
1)一般性的漏洞
遵循的就是普通DevOps发布流程
2)对于比较严重的漏洞,通常由安全、运维、产品3个职能的Leader组织一个会议,制定专门的漏洞修补和应急计划。
3)SLA——根据漏洞类型和影响程度决定,一般性的漏洞也不必连夜修复。
4)假如短时间内无法修复,使用临时规避措施
3.技术
1)发现得快依赖于入侵感知体系
2)修得快则依赖于持续集成和自动化发布工具的支持
3)自动化运维能力主要属于运维的职责,但也会影响漏洞修复和安全策略实施的效率。
总结一下,实际上有3件事:1)发现的快;2)修的快;3)修不了,临时规避。运营环节
防御体系建设的一大过程就是跟逃逸和绕过既有的安全策略做对抗,单点的检测手段不足;选取的检测维度不够;覆盖率不足;安全产品的可用性;数据质量;人的问题。漏报的根因分析。在一轮又一轮螺旋式的迭代中不断地改进既有安全体系的能力,这将占据了日常主要的工作量。